
Annotation errors can reduce ML model accuracy by up to 26%. This guide explains why data annotation quality matters for AI success, with real project case studies, accuracy benchmarks by industry, best practices for quality assurance, and operational insights from managing 300+ annotators at scale.
Contents
- What Annotation Quality Actually Means (Beyond Definitions)
- How Poor Annotation Destroys ML Models: The Evidence
- Case Study 1: Object Detection for Autonomous Systems
- Case Study 2: Medical Image Classification
- Case Study 3: NLP Sentiment Analysis for Retail
- What We’ve Learned: Operational Insights from 300+ Annotators
- The Annotation Workflow That Actually Works
- Common Annotation Mistakes and How to Prevent Them
- The Human-in-the-Loop Advantage
- Data Annotation Best Practices for ML Teams
- Conclusion
- FAQ
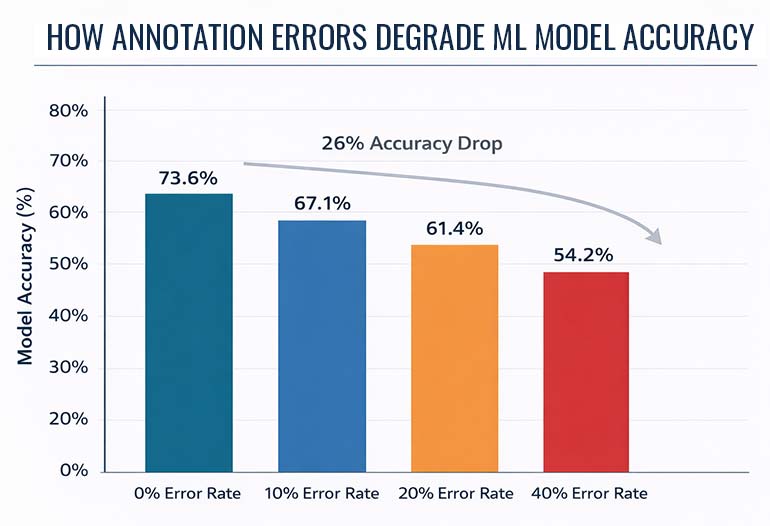
Your algorithm is only as intelligent as the data it learns from. In controlled experiments, annotation errors reduced model accuracy from 73.6% to 54.2% – a 26% performance collapse from labeling mistakes alone.
Yet most organizations treat annotation as a commodity task rather than a precision engineering discipline. This disconnect is why 60% of AI projects are predicted to fail due to data quality issues by 2026.
This article is not a textbook definition of data annotation. It examines why annotation quality is the single most important factor determining whether ML models succeed or fail – supported by research evidence, real case studies, and operational insights from managing large-scale annotation teams.
The data annotation market is projected to reach $29 billion by 2032, growing at 29.1% CAGR. Roughly 80% of ML effort is now spent on data preparation and labeling. The investment is enormous – and the margin for error is razor-thin.
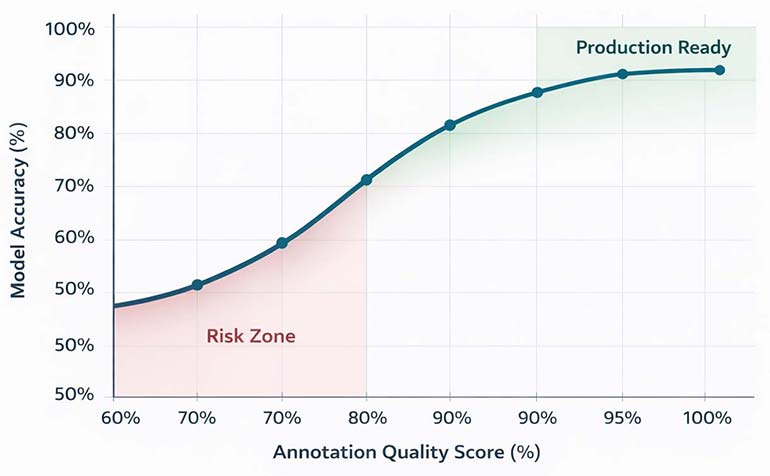
What Annotation Quality Actually Means (Beyond Definitions)
Most articles define data annotation as “labeling data for machine learning.” That’s technically correct but operationally useless. Quality annotation is a precision engineering discipline.
Annotation quality is measured by three concrete metrics: accuracy (how closely labels match ground truth), consistency (inter-annotator agreement scores), and completeness (coverage of edge cases and rare classes).
An inter-annotator agreement score above 0.8 (measured by Cohen’s Kappa or Fleiss’ Kappa) is the threshold for reliable training data. Below 0.7, your model is learning from noise.
Leading annotation service providers track all three metrics across every project. Industry best practice requires 95%+ labeling accuracy, 0.85+ inter-annotator agreement, and documented edge-case coverage before any dataset is considered production-ready.
How Poor Annotation Destroys ML Models: The Evidence
The relationship between annotation quality and model performance is not theoretical. Controlled research has quantified the damage precisely.
When researchers introduced labeling errors – additional bounding boxes, missing boxes, and shifted boxes – into training data, model accuracy dropped from 73.6% to 54.2%. That’s a 26% performance collapse.
The errors compound during training. Small labeling mistakes amplify into significant performance degradation because the model learns incorrect patterns as if they were ground truth.
A separate study found that even gold-standard benchmark datasets contain quality issues. Pervasive label errors in widely-cited datasets mean the entire ML research ecosystem sometimes builds on flawed foundations.
IBM’s 2025 research found that 43% of chief operations officers identify data quality as their most significant data priority. And Gartner predicts that 60% of AI projects will be abandoned by organizations lacking AI-ready data through 2026.
The bottom line: fixing annotation errors in production AI systems costs 10-100x more than addressing them during the labeling phase. Invest in quality upfront, or pay exponentially later.
Case Study 1: Object Detection for Autonomous Systems
Project Snapshot
- ML Use Case: Pedestrian and vehicle detection for ADAS (Advanced Driver Assistance Systems)
- Dataset: 45,000 urban driving images across 12 weather/lighting conditions
- Annotation Types: Bounding boxes, polygon segmentation, 3D cuboids for LiDAR data
- Team: 28 annotators + 4 QA reviewers over 6 weeks
The Challenge
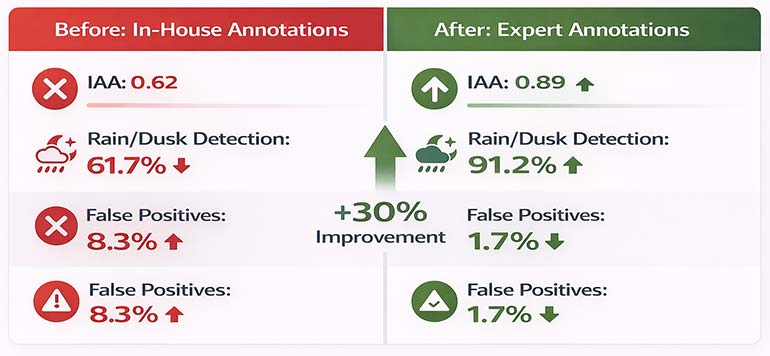
The client’s initial in-house annotations had an inter-annotator agreement of 0.62 – well below the 0.8 threshold. Their object detection model was misclassifying pedestrians at dusk and in rain conditions.
Edge cases were the root cause. Partially occluded pedestrians, reflective surfaces in wet conditions, and shadows at low sun angles were inconsistently labeled across the dataset.
What We Did
We developed a 47-page annotation guideline specifically for this project. It included visual examples of 23 edge-case categories identified from the client’s failure analysis.
Annotators completed a 3-day calibration program before touching production data. Each annotator had to achieve 93%+ accuracy on a 500-image gold-standard test set.
We implemented a two-stage QA process: automated IoU checks flagged annotations below 0.75 threshold, followed by human expert review of all flagged items.
The Results
| Metric | Before (Client In-House) | After (HabileData) |
|---|---|---|
| Inter-annotator agreement | 0.62 | 0.89 |
| Pedestrian detection accuracy (clear) | 84.1% | 96.3% |
| Pedestrian detection accuracy (rain/dusk) | 61.7% | 91.2% |
| False positive rate | 8.3% | 1.7% |
| Model retraining cycles needed | 7 iterations | 2 iterations |
The 30-percentage-point improvement in adverse-condition detection came entirely from better annotation quality – the model architecture was unchanged.
Case Study 2: Medical Image Classification
Project Snapshot
- ML Use Case: Tumor boundary detection in MRI scans
- Dataset: 12,000 MRI images across 4 tumor types
- Annotation Types: Pixel-level semantic segmentation with polygon masks
- Team: 8 specialized annotators with medical imaging training + 2 radiologist reviewers
The Challenge
Medical imaging annotation requires domain expertise that general annotators lack. The client’s previous vendor achieved only 78% Dice coefficient – insufficient for clinical-grade AI.
The primary failure was boundary precision. Tumor margins in MRI scans are inherently ambiguous. Without radiologist-guided annotation guidelines, annotators drew boundaries inconsistently.
What We Did
We assigned annotators who had completed our 40-hour medical imaging certification program. Each annotator specialized in specific tumor types to build deep pattern recognition.
We implemented consensus annotation: every image was labeled by three independent annotators. Disagreements were resolved by a radiologist consultant. This process is slower but produces gold-standard quality.
The Results
| Metric | Previous Vendor | HabileData |
|---|---|---|
| Dice coefficient | 0.78 | 0.93 |
| Boundary IoU | 0.71 | 0.90 |
| Inter-annotator agreement | 0.69 | 0.91 |
| Clinician validation pass rate | 64% | 97% |
The model trained on our annotations achieved clinical validation approval – the previous dataset had been rejected twice by the regulatory review board.
Case Study 3: NLP Sentiment Analysis for Retail
Project Snapshot
- ML Use Case: Customer review sentiment classification (positive/negative/neutral/mixed)
- Dataset: 85,000 product reviews across 6 languages
- Annotation Types: Sentiment labels, entity tagging, intent classification
- Team: 15 annotators (multilingual) + 3 QA specialists over 4 weeks
The Challenge
Sarcasm and cultural context made automated sentiment pre-labeling unreliable. The client’s AI-only approach misclassified 31% of sarcastic reviews as positive.
Multi-language reviews added complexity. Sentiment expressions in German, Japanese, and Portuguese follow different linguistic patterns than English.
What We Did
We assigned native-speaker annotators for each language. Each team completed language-specific calibration sessions with 200 pre-labeled examples including sarcasm edge cases.
We used a hybrid approach: AI pre-labeling handled straightforward cases (70% of volume), while human annotators focused on ambiguous, sarcastic, and mixed-sentiment reviews.
The Results
| Metric | AI-Only Labels | Human-in-the-Loop |
|---|---|---|
| Overall sentiment accuracy | 72.4% | 94.1% |
| Sarcasm detection accuracy | 38% | 87% |
| Cross-language consistency | 61% | 92% |
| F1-score (mixed sentiment) | 0.54 | 0.88 |
The retailer’s customer insight team reported a 41% improvement in actionable insight extraction from review data after the model was retrained on our annotations.
What We’ve Learned: Operational Insights from 300+ Annotators
After managing thousands of annotation projects, certain patterns emerge that no textbook covers. Here are operational insights documented from large-scale annotation team management.
The Most Common Annotation Mistake
Inconsistent edge-case handling is the number-one quality killer. It’s not typos or obvious errors – it’s the ambiguous cases where two reasonable annotators make different decisions.
In our QA data, edge-case inconsistency accounts for 62% of all annotation disagreements. The fix is never “try harder” – it’s always better documentation of edge cases with visual examples.
Annotator Training Duration vs. Output Quality
Our internal data shows a clear inflection point. Annotators who complete 20+ hours of project-specific training produce 34% fewer errors than those with under 10 hours of training.
However, beyond 40 hours, additional training shows diminishing returns. The sweet spot for most annotation tasks is 20–30 hours of calibrated training before production work begins.
Optimal Batch Size for Review Cycles
We’ve tested batch sizes from 50 to 5,000 items per review cycle. The optimal size is 200-500 annotations per review batch.
Smaller batches catch errors faster but create review bottlenecks. Larger batches let systematic errors propagate before detection. The 200-500 range balances speed with quality control.
What Accuracy Threshold Is “Good Enough”?
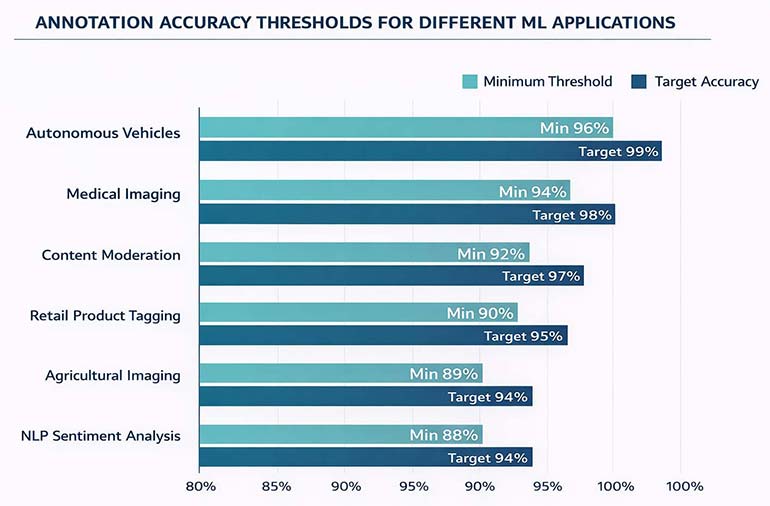
It depends entirely on the downstream application. Here’s what we’ve found across our project portfolio:
| ML Application | Minimum Accuracy | Target Accuracy | Critical Metric |
|---|---|---|---|
| Autonomous vehicles | 96% | 99%+ | Boundary IoU ≥ 0.85 |
| Medical imaging | 94% | 98%+ | Dice coefficient ≥ 0.90 |
| Retail product tagging | 90% | 95%+ | Classification F1 ≥ 0.90 |
| NLP sentiment analysis | 88% | 94%+ | IAA ≥ 0.80 |
| Content moderation | 92% | 97%+ | Recall ≥ 0.95 |
| Agricultural imaging | 89% | 94%+ | Segmentation IoU ≥ 0.80 |
Safety-critical applications (autonomous vehicles, medical AI) require near-perfect accuracy. Non-safety applications can tolerate slightly lower thresholds while still delivering strong model performance.
The Annotation Workflow That Actually Works
A structured, repeatable workflow is the difference between consistent quality and unpredictable output. Here’s a process refined across thousands of annotation projects.
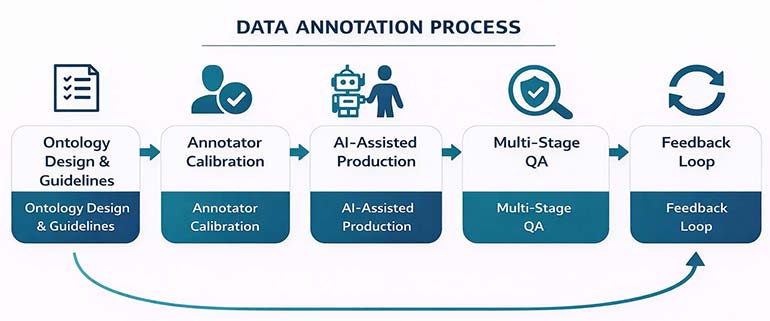
Stage 1: Ontology Design & Guideline Development
Before any labeling begins, we co-develop the annotation ontology with the client’s ML team. This defines every class, edge case, and decision boundary in a formal document.
Our guidelines typically run 30-50 pages. They include visual examples for every edge case category. Annotators reference this document continuously during production.
Stage 2: Annotator Selection & Calibration
We match annotators to projects based on domain expertise, language skills, and past performance on similar tasks. Not every annotator works on every project.
Calibration involves annotating a 200-500 sample gold-standard set. Annotators must achieve the project’s minimum accuracy threshold before accessing production data.
Stage 3: Production Annotation with AI Assistance
For suitable tasks, AI pre-labeling handles straightforward cases (typically 50-70% of volume). Human annotators focus on complex, ambiguous, and edge-case items.
This hybrid approach reduces annotation time by 60-80% while maintaining quality. The key is never allowing AI pre-labels to ship without human verification.
Stage 4: Multi-Stage Quality Assurance
- Automated QA: checks formatting, boundary thresholds (IoU), label distribution, and completeness. This catches 40% of errors instantly.
- Human QA review: targets the remaining items, focusing on semantic accuracy that automated checks cannot assess. Reviewers have senior-level expertise.
- Consensus validation: is used for high-stakes projects. Three annotators label each item independently, and disagreements trigger expert arbitration
Stage 5: Feedback Loop & Continuous Improvement
Post-delivery, we analyze model performance data from the client to identify annotation patterns that correlate with errors. This feeds back into guideline updates.
Every project improves the next. Mature annotation operations build internal knowledge bases containing thousands of documented edge cases across multiple industry verticals.
Common Annotation Mistakes and How to Prevent Them

1. Vague Annotation Guidelines
- The problem: Generic instructions like “label all vehicles” leave too much to interpretation. Does “vehicle” include bicycles? Scooters? Parked vs. moving?
- The fix: Write exhaustive class definitions with inclusion/exclusion criteria and visual examples. Test guidelines on 5 annotators before scaling.
2. Skipping Calibration
- The problem: Sending annotators directly into production without calibration sessions. They learn on your data – creating a gradient of quality from first to last batch.
- The fix: Require every annotator to pass a gold-standard test achieving 90%+ accuracy before production access. Re-calibrate weekly.
3. Ignoring Class Imbalance
- The problem: Rare but critical classes (e.g., emergency vehicles, rare diseases) get under-annotated. Models learn to ignore them.
- The fix: Deliberately oversample rare classes in annotation batches. Set minimum annotation counts per class before considering a dataset complete.
4. Over-Relying on AI Pre-Labels
- The problem: Accepting AI-generated labels without human verification. Pre-labeling models carry their own biases and failure modes.
- The fix: Treat AI pre-labels as suggestions, never ground truth. Require human review of 100% of pre-labeled items, with extra scrutiny on edge cases.
5. Delayed QA Feedback
- The problem: Running QA only after the entire batch is complete. Systematic errors propagate across thousands of items before detection.
- The fix: Implement rolling QA on batches of 200–500 items. If error rate exceeds 15% in any batch, pause production and re-calibrate.
The Human-in-the-Loop Advantage
AI-assisted annotation tools are powerful. But they cannot replace human judgment for ambiguous, contextual, and safety-critical labeling tasks.
Over 80% of companies deploying AI now maintain human-in-the-loop processes. This is not about distrust of automation. It’s about understanding where machines and humans each add the most value.
- Machines excel at: volume processing, format validation, detecting obvious outliers, and consistent rule application across large datasets.
- Humans excel at: contextual understanding, sarcasm and irony detection, cultural nuance, ambiguous boundary decisions, and ethical judgment calls.
The EU AI Act, effective August 2026, mandates that high-risk AI systems be designed for effective oversight by “natural persons.” Human-in-the-loop annotation is no longer just a quality choice – it’s becoming a legal requirement.
Learn more: How Human-in-the-Loop Boosts AI Data Annotation
Data Annotation Best Practices for ML Teams
1. Define Quality Before You Define Quantity
Establish measurable quality metrics (accuracy targets, IAA thresholds, boundary precision requirements) before discussing dataset size. A smaller, perfectly annotated dataset consistently outperforms a large, noisy one.
2. Invest in Annotator Expertise, Not Just Headcount
Domain-trained annotators produce significantly better output than general-purpose labelers. For medical, legal, and autonomous driving applications, annotator expertise directly determines model reliability.
3. Build Feedback Loops Between Annotation and Model Training
Connect model performance metrics back to specific annotation patterns. High-error categories in your model often trace directly to inconsistent or ambiguous annotations in those same categories.
4. Version Your Annotation Guidelines
As projects evolve, guidelines must evolve too. Track changes, document edge-case additions, and ensure all annotators work from the same version. Guideline drift causes quality drift.
5. Measure Continuously, Not Just at Delivery
Annotation quality is not a one-time assessment. Implement rolling QA, weekly calibration checks, and monthly trend analysis. Quality degrades when it’s not actively maintained.
6. Choose the Right Annotation Type for Your Task
The choice between bounding boxes, polygons, and semantic segmentation has direct cost and accuracy implications. Bounding boxes are 3-5x faster but less precise. Semantic segmentation is pixel-accurate but 8-10x more expensive.
Explore annotation types in depth: Image Annotation Types Guide
Conclusion
Data annotation is not a preprocessing step. It is the engineering discipline that determines whether your ML model succeeds in production or fails at deployment.
The evidence is clear: annotation errors can collapse model accuracy by 26%. The cost of fixing bad labels in production is 10-100x higher than getting them right the first time.
After 3,100+ projects, we’ve learned that quality comes from three things: rigorous guidelines, trained annotators, and structured QA processes. No shortcuts exist.
Invest in annotation quality. Your model’s performance depends on it.
FAQs About Data Annotation for Machine Learning
Machine learning models learn from labeled examples. Without accurate annotations, models cannot distinguish objects, understand language, or make reliable predictions. Annotation quality directly determines model accuracy – poor labels produce poor AI.
Costs vary by complexity. Simple image classification runs $0.02-$0.10 per image. Bounding box annotation costs $0.05-$0.30 per image. Semantic segmentation ranges from $0.50-$6.00 per image. NLP annotation typically costs $0.03-$0.15 per text unit.
These terms are used interchangeably. “Data labeling” typically refers to the act of assigning tags, while “data annotation” encompasses the broader process including context, relationships, and metadata addition. Functionally, they describe the same practice.
Research shows annotation errors can reduce model accuracy by up to 26%. The impact is compounding — small labeling mistakes amplify during training. Fixing annotation errors in production costs 10–100x more than addressing them during labeling.
Outsourcing is more cost-effective for most organizations. Specialized vendors maintain trained annotator teams, established QA workflows, and domain expertise across multiple verticals. Build in-house only if annotation is a continuous, core business function.
Common platforms include CVAT (open-source), Labelbox (enterprise), V7 (video-focused), Supervisely, and SuperAnnotate. The right choice depends on your data types, scale requirements, and integration needs with your ML pipeline.
Timeline depends on dataset size, annotation complexity, and quality requirements. A 10,000-image bounding box project typically takes 1-2 weeks. Semantic segmentation of the same volume takes 3-5 weeks. NLP annotation at scale can run 2-6 weeks.
Need Production-Grade Data Annotation?
HabileData’s 300+ annotator team delivers 99.5%+ accuracy across computer vision, NLP, and autonomous systems. 3,100+ projects completed. 10,000+ images processed daily.
Talk to Our Annotation Team »


Snehal Joshi , Head of Business Process Management at HabileData, leads a 500-member team of data professionals, having successfully delivered 500+ projects across B2B data aggregation, real estate, ecommerce, and manufacturing. His expertise spans data hygiene strategy, workflow automation, database management, and process optimization - making him a trusted voice on data quality and operational excellence for enterprises worldwide. 🔗Connect with Snehal on LinkedIn


