
Text annotation for NLP is the work of labeling text so machines can read it for context, intent, and meaning. This guide walks through the annotation types, the tools we actually use, the workflow we run on production projects, and when outsourcing makes sense – based on 500+ AI projects at HabileData
Contents
- What is text annotation in NLP?
- 8 types of text annotation, with real use cases
- Manual vs. automated vs. semi-automated annotation
- The text annotation workflow we run on production NLP projects
- Text annotation best practices, from real NLP projects
- Text annotation tools compared (from hands-on use)
- How human-in-the-loop (HITL) raises annotation accuracy
- Outsource text annotation or build in-house? A decision framework
- Industry use cases for text annotation
- Where text annotation is heading in the LLM era
- Conclusion
- FAQ
Most NLP models in production don’t perform like they did in the lab. In our experience, the gap is rarely caused by the architecture; the labels the model learned from are usually the problem. That’s why we keep coming back to the same conclusion: whether handled in-house or through text annotation services, text annotation is the highest-leverage step in the whole pipeline, and the one teams most often underinvest in.
Text annotation means labeling words, phrases, and sentences in a dataset so a model can learn to recognize entities, classify intent, read sentiment, and parse grammar. Get it right and your chatbot resolves issues. Get it wrong and the same chatbot frustrates customers in five different ways before escalating.
This guide is written from the operations side. We’ve annotated tens of millions of text records across legal, financial, healthcare, real estate, and e-commerce data. The patterns, tool choices, mistakes, and quality bars below come out of that work – not a vendor pitch deck.
Text annotation for NLP is the labeling of text – entities, sentiments, intents, parts of speech – so machine learning models can understand language. The most common types are entity annotation, sentiment annotation, text classification, intent labeling, and part-of-speech tagging. To get usable accuracy you typically need clear guidelines, trained annotators, multi-stage QA, and inter-annotator agreement above 0.80.
What is text annotation in NLP?
Text annotation in NLP means marking up unstructured text with labels – names, places, sentiments, intents, grammatical roles, relationships. Those labels become the supervised signal a model learns from.
Without annotation, a model has no ground truth. Even modern large language models depend on labeled data for fine-tuning, instruction following, RLHF, and domain adaptation. The technique that powered BERT in 2018 still powers LLM alignment in 2026 – the surface keeps changing, the dependency on humans labeling data does not.
Why annotation quality decides model performance
A model trained on inconsistent labels gives you inconsistent predictions. We have watched NER models lose 12 to 18 points of F1 because two annotators couldn’t agree on whether a job title should be tagged as PERSON or ROLE. The model wasn’t broken. The label set was.
The fix is almost never a bigger model. It’s tighter guidelines, properly calibrated annotators, and QA that doesn’t get cut for time – which is exactly what gets cut when teams treat labeling as a commodity.
8 types of text annotation, with real use cases
Picking the wrong annotation type is the most common mistake we see in client briefs. Match the annotation type to what the model needs to learn before you scope cost or timeline.

1. Entity annotation (Named Entity Recognition)
Labeling people, organizations, locations, products, dates, monetary values inside a text. Foundation of NER models. Use cases:
- Healthcare: pulling drug names, dosages, and conditions out of clinical notes
- Legal: tagging case citations, statutes, parties, and jurisdictions in contracts
- Finance: identifying companies, tickers, and amounts in earnings transcripts
2. Entity linking
Goes a step past entity annotation by tying each entity to a unique record in a knowledge base – for example, linking “Apple” to the Apple Inc. entry in Wikidata, not the fruit. This is what stops your model from confusing the company with the fruit, or two different people with the same name.
- Journalism: disambiguating people and organizations across news archives
- Pharma research: mapping drug mentions to standardized chemical IDs (e.g., DrugBank)
3. Text classification
Assigns one label or several labels to a passage of text. The label set is whatever the project needs – topics, departments, urgency tiers, languages.
- Customer support: routing tickets to billing, technical, or account teams without a human in the middle
- Content moderation: flagging policy violations across categories like hate speech, spam, and self-harm
4. Sentiment annotation
Labels polarity (positive, negative, neutral) and sometimes intensity, or which aspect of something the opinion is about. Aspect-based sentiment is much harder than overall sentiment and the guidelines have to be tighter.
- E-commerce: identifying which product attribute drove a negative review (battery, shipping, build quality)
- Brand monitoring: tracking sentiment toward a brand across social platforms during a campaign
5. Intent labeling
Tags the goal behind a query. This is the foundation of conversational AI. A single sentence can carry more than one intent, and detecting them together is harder than the demos make it look.
- Chatbots: telling a ‘book’ intent apart from ‘cancel’ or ‘modify’
- Voice assistants: separating ‘play music’ from ‘find music’ from ‘identify music’
6. Part-of-speech (POS) tagging
Tags each token with its grammatical role: noun, verb, adjective, determiner. POS tags feed dependency parsers, machine translation, and text-to-speech.
7. Coreference resolution
Identifies when different words point at the same entity – “Sundar Pichai,” “the CEO,” and “he” all referring to one person across an article. Coreference is what makes document-level understanding and summarization actually work.
8. Linguistic and semantic annotation
Captures structure and meaning – syntactic dependencies, semantic roles (who did what to whom), discourse relations between sentences. Mostly research-grade NLP and academic corpora, though some enterprise document AI projects need it too.
Manual vs. automated vs. semi-automated annotation
There is no single best annotation approach. The right choice depends on dataset size, language complexity, how much error you can absorb, and budget. Here’s how the three common approaches compare:
| Approach | Best for | Accuracy ceiling | Throughput | Cost |
|---|---|---|---|---|
| Manual | Small datasets, ambiguous domains, regulated industries (legal, medical) | 95–99% | Low – 50 to 500 records per annotator per day | High |
| Automated | Massive datasets, well-defined entity types, low ambiguity | 70–85% | Very high – millions of records per day | Low |
| Semi-automated (HITL) | Most production NLP work that needs both quality and scale | 92–98% | High – 5,000 to 50,000 records per day per team | Moderate |
Most production work – including most of ours – runs as semi-automated with human review. Pure manual gets too slow once you cross 100,000 records. Pure automation is too unreliable for anything past simple classification. The hybrid wins on the dimensions that actually matter.
The text annotation workflow we run on production NLP projects
A disciplined workflow is what separates an annotation project that ships in 30 days from one that drifts for 90. The workflow below is what we use across NLP engagements; it has been tightened over hundreds of projects, and it still gets revised every few months.
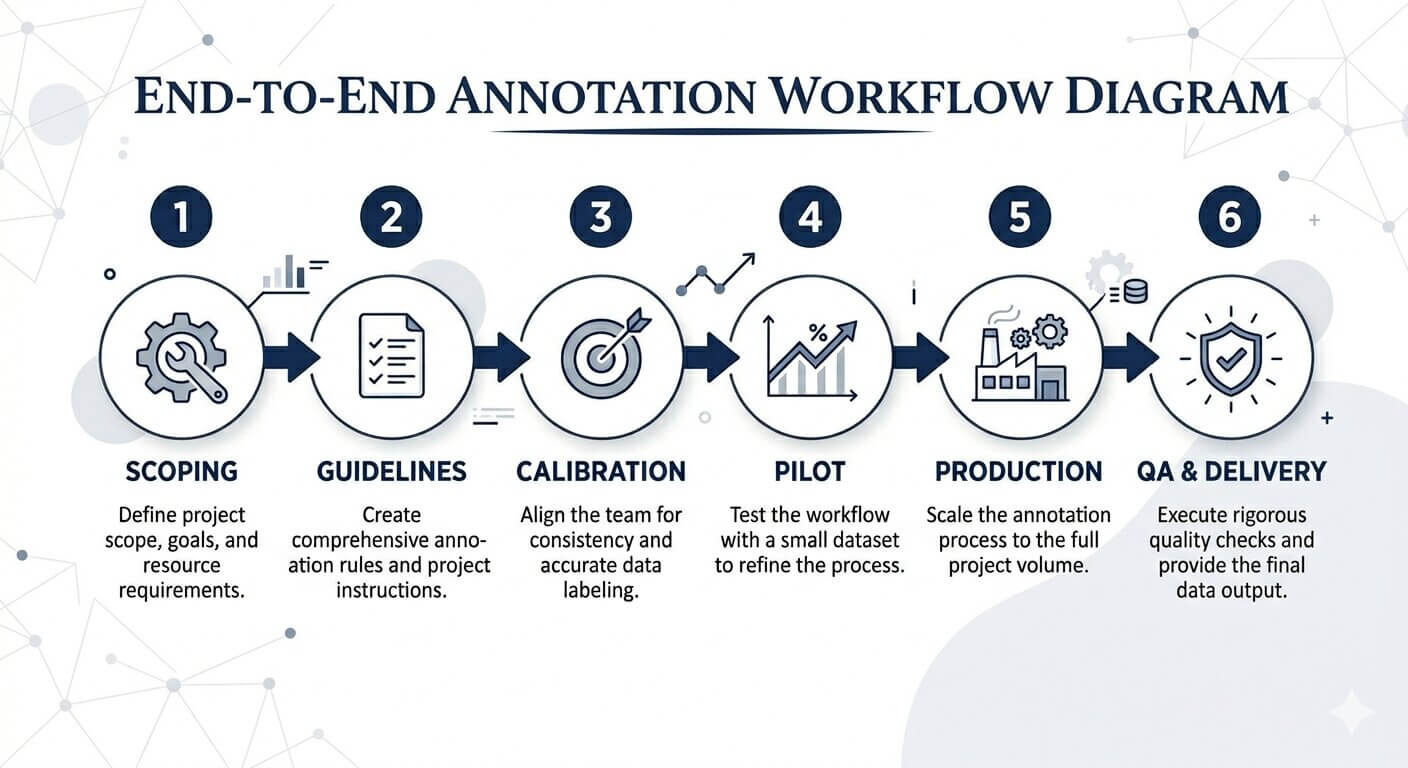
Step 1: Project scoping and ontology design
Before anyone touches data, define the label set, its hierarchy, and the boundary cases. A poorly designed ontology can’t really be patched – it has to be redone, and that’s the most expensive failure mode in annotation.
Step 2: Guideline authoring with edge-case bank
Write annotation guidelines that include positive examples, negative examples, and a living bank of edge cases pulled out of the pilot. We typically iterate guidelines three to five times before locking them. If you lock them earlier you’re going to be unlocking them in week three.
Step 3: Annotator selection and calibration
Annotators take a calibration test on 100 to 200 gold-standard examples. Anyone scoring below 90% agreement with the gold set gets retrained or reassigned. This single step prevents most of the quality problems that show up later.
Step 4: Pilot annotation (2,000 to 5,000 records)
Run a pilot at 5–10% of total volume. Measure inter-annotator agreement (Cohen’s kappa or Krippendorff’s alpha), surface ambiguous cases, update guidelines. Locking guidelines without a pilot is the single biggest waste of project hours we see, and we see it constantly.
Step 5: Production annotation with sampled QA
Move into full production with a sampled QA pass on 10–20% of output. Senior reviewers re-annotate the sample blind and compare against the primary annotator’s labels. If disagreement goes above 5%, the guideline gets reviewed before more data flows through.
Step 6: Final QA and delivery format conversion
Convert annotations into whatever format the model expects – JSON, CoNLL, BIO tags, spaCy DocBin, Hugging Face datasets – and run automated schema validation before delivery. Skip this step and format errors will silently break model training somewhere downstream.
Text annotation best practices, from real NLP projects
Most annotation guides repeat the same generic advice. The points below are the specific things we wish we’d known on our first 10 NLP projects, and that we now bake into every new engagement.
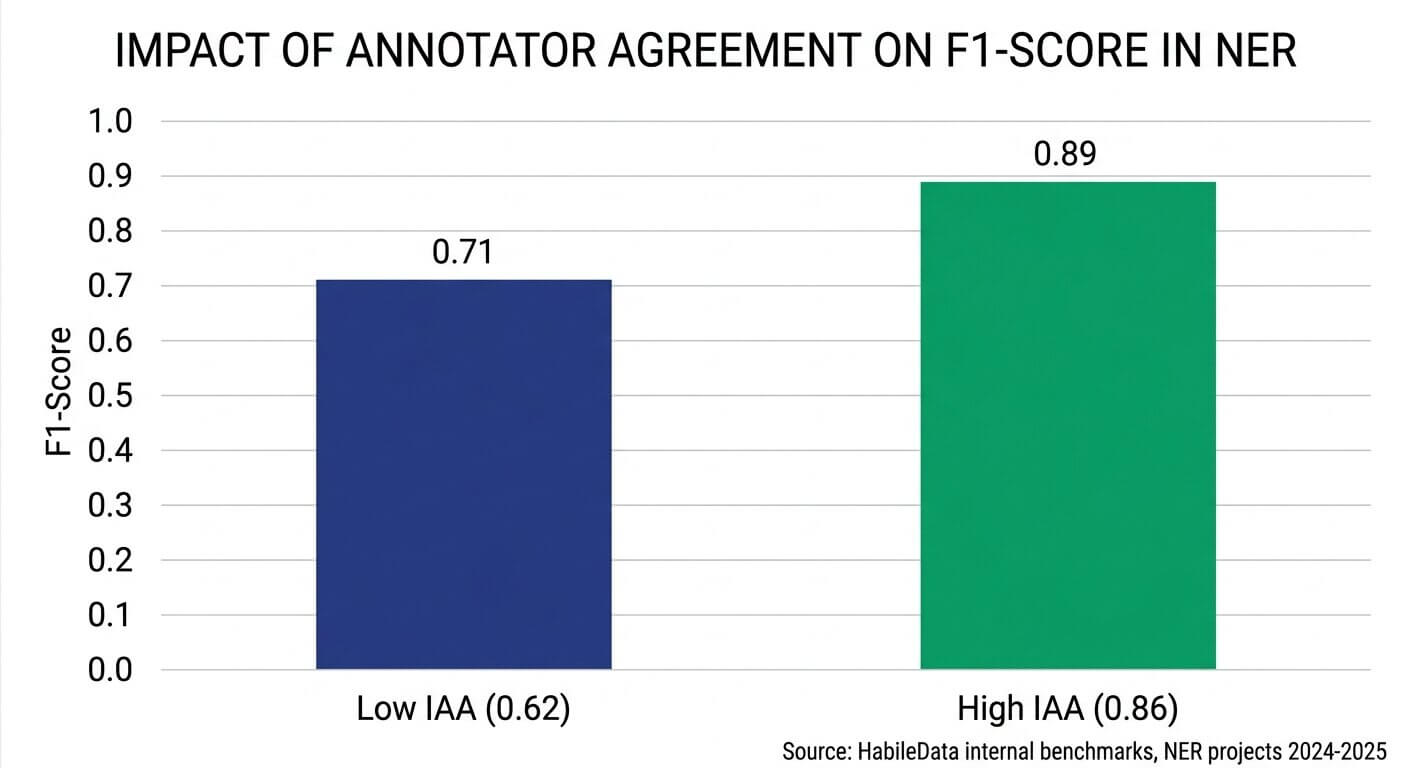
Lock annotator agreement before you scale annotators
Inter-annotator agreement (IAA) is the single best predictor of final model quality we’ve found. Aim for Cohen’s kappa above 0.80 for entity tasks, above 0.75 for sentiment, before you scale beyond a pilot team.
If you’re below those numbers, adding annotators makes the dataset noisier, not more representative. We’ve turned down projects that demanded a faster ramp because the pilot IAA was 0.61 – at that level, no amount of additional annotation would have produced a usable model.
Treat NER edge cases as guideline failures, not annotator failures
When two skilled annotators disagree on where a named entity starts and ends, the guideline is wrong, not the annotators. Common cases that need explicit rules: nested entities (“Bank of America Corporation”), enumerations (“John, Mary, and the team”), and titles attached to names (“CEO Tim Cook”). There are more – keep adding as you find them.
Keep an edge-case appendix in the guideline document, and version it. We tag every edge-case decision with the date and the project it came from, so annotators carry institutional memory across engagements instead of relearning the same lessons.
For sentiment annotation, calibrate on the hard middle
The mistake here is calibrating annotators on obvious positives and obvious negatives. The labels that actually move model performance are the messy boundary cases – “It works, but the price is high,” or “Better than the last version, still not great.”
We build calibration sets that are 60% boundary cases on purpose. An annotator who can label clear positives and negatives accurately is not yet ready for production sentiment work.
Use blind double annotation on the ambiguous tasks
For coreference, intent labeling, and aspect-based sentiment, single-pass annotation is unreliable. Run two annotators independently, then resolve disagreements with a senior adjudicator. Yes, this adds 60–80% to the labeling cost. In our experience it also adds 8–15 points to model F1 scores, which usually pays for itself before you even ship.
Sample QA can’t be random
Random QA sampling underweights the cases that actually matter. We stratify QA samples by difficulty score (length, entity density, language register) so 30–40% of the sample comes from the hardest decile. That’s where labeling drift shows up first, and where you want to catch it.
Track inter-annotator agreement weekly, not at delivery
Annotation drift is gradual. Weekly IAA tracking surfaces it before 50,000 mislabeled records hit production. Pin a kappa dashboard in the team’s daily standup – it changes behavior more than any guideline document does.
Text annotation tools compared (from hands-on use)
Tool selection should follow the workflow, not lead it. The notes below come from our team’s actual production use of each tool, not from feature lists on vendor websites.
| Tool | Best for | Strengths | Limitations |
|---|---|---|---|
| Prodigy | Active learning, model-in-the-loop projects, NER refinement | Tight integration with spaCy, fast keyboard-driven UI, scriptable recipes; annotator productivity is genuinely high | Single-machine workflows, weak multi-user collaboration, paid license per seat |
| Doccano | Open-source projects, smaller teams, classification & sequence labeling | Free, easy to self-host, clean UI for sentiment and classification, multi-language support | Limited automation, no built-in QA tooling, basic export formats only |
| Label Studio | Mixed-modality projects (text + image + audio), enterprise teams | Highly configurable, supports team management and review workflows, ML backends, strong active learning | Configuration complexity, learning curve for new annotators, performance dips on very large projects |
| Amazon SageMaker Ground Truth | AWS-native pipelines, large-scale projects with managed workforces | Auto-labeling at scale, integrated with SageMaker training, built-in workforce management | AWS lock-in, opaque per-record pricing, less flexible for custom ontologies |
| spaCy + custom UI | Teams already using spaCy in production training pipelines | Format compatibility eliminates conversion errors, full control over UI behavior | Requires engineering investment, no out-of-the-box collaboration features |
| LightTag / Tagtog | Document-level NLP, biomedical and legal corpora | Strong document-level annotation, good coreference and relation tools, web-based collaboration | Pricing tiers, smaller community, fewer integrations than Label Studio |
Our rough pattern: Prodigy when active learning materially cuts volume, Label Studio when team collaboration matters, Doccano when budget is the constraint, SageMaker Ground Truth when the rest of the stack is already on AWS. We don’t recommend a single tool across all projects – the fit shifts with the use case, and pretending otherwise is how teams end up using the wrong tool for two years.
How human-in-the-loop (HITL) raises annotation accuracy
Pure automation rarely clears 85% accuracy on production NLP tasks. Pure manual annotation doesn’t scale economically past a few hundred thousand records. Human-in-the-loop combines them: the model pre-labels, humans correct, corrections retrain the model, and the cycle keeps tightening.
Where HITL helps most
- Long-tail entities: models miss rare entities that humans pick up immediately, especially in domain-specific corpora
- Ambiguous sentiment: sarcasm, mixed opinions, and culturally-coded language need human judgment
- Active learning: routing the model’s least-confident predictions to humans focuses the effort where it pays off
- Continuous improvement: every correction becomes new training signal, so accuracy goes up over the project’s lifetime
On a recent NER project for a financial-data client, HITL took entity F1 from 0.78 (model only) to 0.94 (model plus human review), at 38% of the cost of full manual annotation. We’ve covered this pattern in more depth in our piece on how human-in-the-loop boosts AI data annotation.
Outsource text annotation or build in-house? A decision framework
This is the question that actually decides project economics, and most blog posts handle it badly. Here’s the framework we use when advising clients – without putting a thumb on the scale.
In-house annotation makes sense when…
- Your data legally cannot leave your environment (regulated PHI, classified material, certain financial records)
- Annotators need deep domain expertise that’s hard to transfer (licensed radiologists, securities lawyers)
- Annotation is a continuous, low-volume need – under 5,000 records per month – that pairs well with full-time staff
- Your model retraining cycle is daily or hourly and tightly coupled to internal product telemetry
Outsourcing makes sense when…
- Project volume goes past 50,000 records, or has elastic surge requirements
- You need multiple annotation modalities (text, image, audio) and don’t want to staff three teams
- Time-to-first-model matters more than long-term operational ownership
- You need ISO 27001 / SOC 2 certified data handling without building it from scratch
- Your in-house team is bottlenecked on the modeling work, not the labeling work
The economics most teams miss
In-house annotation looks cheaper on a per-record basis, until you load the full costs – recruiting, training, software licenses, QA tooling, manager time, attrition replacement. Loaded costs typically run 2.3 to 3.1 times the unloaded labor cost, and most internal forecasts only look at the unloaded number, which is often the baseline used when comparing with external data annotation services.
Outsourced annotation has a higher sticker price per record, but a lower total cost of ownership for projects above roughly 25,000 records per month. The crossover point depends on annotation complexity and ramp-up time, so the numbers will vary.
30-day pilot recommendation
If you’re evaluating outsourcing, run a 30-day pilot of 10,000 to 25,000 records. Measure inter-annotator agreement, throughput, and QA accuracy against your own gold set. Any serious annotation partner will agree to pilot pricing and SLA-bound metrics. Be cautious of providers who refuse.
Industry use cases for text annotation
Healthcare and life sciences
Clinical NER pulls conditions, medications, dosages, and adverse events out of unstructured notes. De-identification annotation removes the 18 PHI categories under HIPAA. Pharmacovigilance pipelines depend on adverse-event reports being annotated accurately, because every miss is a regulatory risk.
Legal and contract intelligence
Contract clause annotation trains models to extract terms, parties, jurisdictions, and obligations from agreements. Litigation-support annotation classifies documents in discovery by relevance and privilege – a task where speed and judgment have to coexist.
Financial services
Earnings-transcript annotation captures forward-looking statements, sentiment shifts, and named entities. KYC pipelines use entity linking to map mentioned counterparties to internal customer records, so a name in a news article actually resolves to the right account.
E-commerce
Product-attribute extraction annotates titles and descriptions to populate structured catalog fields. Aspect-based sentiment annotation on reviews powers feature-level product analytics that drive merchandising decisions.
Customer support and CX
Intent and entity annotation power ticket routing and self-service deflection. Sentiment annotation surfaces escalation candidates before they churn – which is more useful than identifying them after.
Case in practice – German construction technology client
A Germany-based construction-tech firm aggregates real-time data on USA and European construction projects. Their crawlers auto-classify 80% of incoming articles. The remaining 20% – the long tail of ambiguous text – needs humans.
We processed 10,000+ construction-related articles, tagging project size, location, phase, and cost across categories the auto-classifier couldn’t resolve. A two-step QA review held annotation accuracy above 99%, on a 24-hour rolling SLA.
Outcome: model accuracy improved meaningfully on the long-tail data, project cost dropped by about 50% versus the client’s prior in-house attempt, and the partnership has continued as an ongoing engagement.
Where text annotation is heading in the LLM era
Large language models haven’t eliminated annotation. They’ve reshaped it. The work that matters most in 2026 looks different from what mattered in 2018, and budgets are shifting accordingly.
RLHF and preference annotation
Reinforcement learning from human feedback asks annotators to rank model outputs by helpfulness, accuracy, and safety. Preference annotation is a different skill from entity tagging. It rewards domain experts and tighter rater training, and most general-purpose annotation teams underestimate how different it is.
LLM-as-annotator with human review
LLMs can pre-label entities, classifications, and intents with surprising accuracy. The question is no longer whether to use them. It’s how to combine them with human review without inheriting their biases. Stratified human review of LLM output is the emerging best practice; it’s cheaper than full manual and safer than trusting the model on its own.
Synthetic data generation
LLM-generated synthetic text can supplement annotated datasets in low-resource domains and languages. Synthetic data is not a replacement for real annotated data. It’s a multiplier for it – useful when used carefully, dangerous when treated as a shortcut.
Multimodal annotation
Text rarely arrives alone anymore. Document AI projects need text plus layout annotation. Conversational AI needs text plus speech plus intent. Multimodal annotation pipelines are quietly replacing single-modality ones in production work.
These shifts are why we expanded our practice into multimodal annotation services and synthetic data generation.
Conclusion: precision in annotation is the cheapest way to lift NLP model performance
Across hundreds of NLP projects, the pattern is consistent. Teams that invest in tight ontologies, calibrated annotators, weekly IAA tracking, and human-in-the-loop QA build models that perform in production. Teams that treat annotation as a commodity step rebuild their datasets within a year, usually after blaming the model first.
The frameworks, tools, and practices in this guide are the ones that have produced 99%+ accuracy on real client work – clinical NER, legal contract intelligence, multilingual sentiment, financial entity extraction. Use them, adapt them, and build your annotation discipline around the parts that match your domain.
If you’re scoping a text annotation project, the next decision is whether to build the workflow internally or run a structured pilot with a partner. The pilot framework above is designed to give you a defensible answer in 30 days.
Frequently asked questions about text annotation for NLP
It’s the process of labeling text – words, phrases, sentences – so machine learning models can learn to recognize entities, intent, sentiment, and grammar. It matters because supervised NLP models can only be as accurate as the labels they learn from. In our work, label quality is the largest single driver of model performance in production. Bigger models don’t fix bad labels.
Entity annotation (NER), entity linking, text classification, sentiment annotation, intent labeling, part-of-speech tagging, coreference resolution, and linguistic or semantic annotation. Most production projects combine two or three – for example, intent labeling plus entity annotation in a chatbot dataset.
Match the method to your model objective and data volume. Manual works for small, ambiguous, or regulated datasets. Automated annotation fits very large, low-ambiguity tasks. Semi-automated, human-in-the-loop annotation handles most production NLP work – it’s the only approach we’ve seen deliver both accuracy and scale together.
Cohen’s kappa or Krippendorff’s alpha above 0.80 for entity tasks, above 0.75 for sentiment. Below those thresholds, scaling annotators makes the dataset noisier, not larger. Track agreement weekly, not just at project end – by then it’s too late to fix anything cheaply.
Cost depends on annotation type, language, ontology complexity, and volume. Simple classification typically runs $0.03 to $0.10 per record. Multi-layer NER with QA typically runs $0.15 to $0.60 per record. Specialized domains (clinical, legal) run higher. Outsourced annotation is generally 30–55% cheaper than fully-loaded in-house annotation at volumes above 25,000 records per month.
Keep it in-house if your data can’t leave your environment, the work needs deep domain expertise, or the volume is small and continuous. Outsource if volume goes past 50,000 records, you need surge capacity, or you’re bottlenecked on modeling rather than labeling. Most production AI teams we work with run a hybrid – in-house for sensitive data, outsourced for everything else.
Prodigy is strong on active learning. Label Studio leads on multimodal and team workflows. Doccano is the strongest -source option. SageMaker Ground Truth fits AWS-native stacks. The best tool depends on whether your priority is speed, collaboration, cost, or integration. There’s no single winner here.
Pilot annotation (2,000–5,000 records) typically takes 1–2 weeks. A full project of 100,000 records typically takes 4–8 weeks with a calibrated team. Specialized domains and multi-pass annotation extend timelines. Compressed timelines below these ranges almost always trade quality for speed, and we’d rather flag that up front than discover it in QA.
No. LLMs can pre-label faster than humans, but they inherit biases, hallucinate confidently on edge cases, and can’t be trusted as the final ground truth for training datasets. The current best practice is LLM pre-labeling combined with stratified human review, with humans focusing on the model’s least-confident predictions.
The five we see most: skipping the pilot phase, locking guidelines before edge cases have been discovered, calibrating annotators only on easy examples, sampling QA randomly instead of by difficulty, and tracking inter-annotator agreement only at delivery rather than weekly. Any one of these alone can cost a project 5–15 points of model accuracy.
Planning a text annotation project?
Get a free annotation strategy session with our NLP team. We’ll scope ontology, recommend tools, and benchmark against your gold set.
Talk to our annotation experts »


Snehal Joshi , Head of Business Process Management at HabileData, leads a 500-member team of data professionals, having successfully delivered 500+ projects across B2B data aggregation, real estate, ecommerce, and manufacturing. His expertise spans data hygiene strategy, workflow automation, database management, and process optimization - making him a trusted voice on data quality and operational excellence for enterprises worldwide. 🔗Connect with Snehal on LinkedIn


