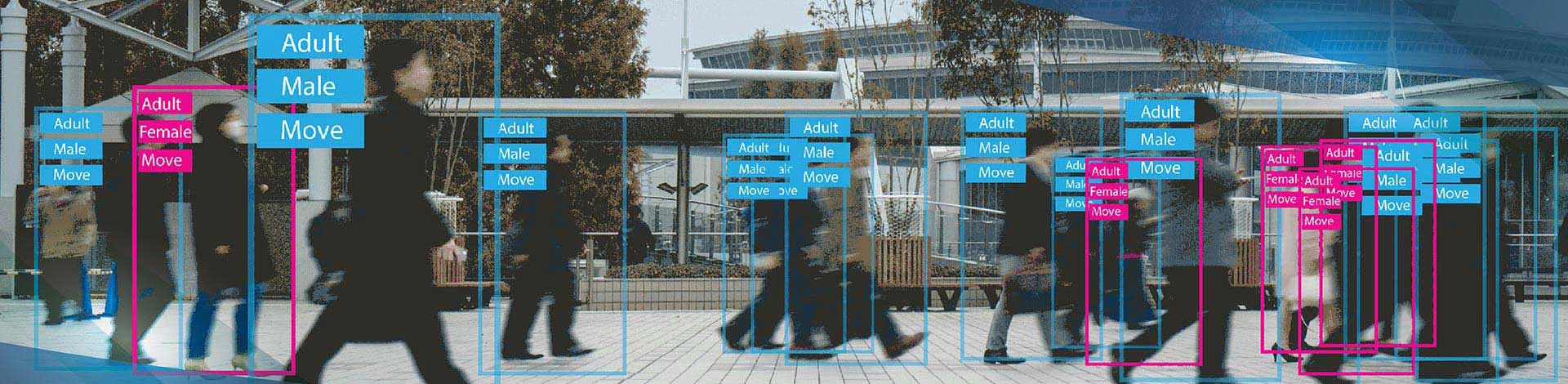
Landmark annotation places precise keypoint coordinates at defined anatomical locations on objects for pose estimation, facial analysis, and gesture recognition AI. HabileData delivers landmark annotation services with 97%+ normalised point distance accuracy across 15+ keypoint schemas, including COCO body pose, MediaPipe face mesh, and dlib facial landmarks. We deliver in COCO keypoints JSON, MediaPipe, and custom formats.
Get started with a free pilot »
Landmark annotation accuracy depends on placing each keypoint within its specific spatial tolerance – not just on the right feature, but at the functionally precise position.
When you outsource landmark annotation services to a generic labeling provider, annotators place points wherever looks approximately right. HabileData is an annotation company where facial and geographic landmark annotators understand Object Keypoint Similarity – placing each point with the precision appropriate to its functional importance in your model, not visual approximation.
Eye corner tolerance vs. nose base tolerance – precision scaled to functional importance
Object Keypoint Similarity (OKS) measures not just whether a keypoint is on the right feature, but whether it falls within the acceptable spatial tolerance for that specific feature. The outer corner of the eye has a much smaller tolerance than the base of the nose, because face recognition models are far more sensitive to eye corner position.
68-point to 468-point schemas – occluded faces, extreme poses, and 50-subject frames
We work with 68-point DALI standard, 98-point extended, 106-point dense mesh, and MediaPipe 468-landmark face mesh schemas. We handle occluded faces obscured by hands, hair, glasses, or masks, multi-face images with up to 50 simultaneous subjects, extreme head poses, and diverse ethnic and demographic facial morphologies that generic teams handle inconsistently.
Satellite, aerial, drone, and street-level – geographic landmarks with GPS precision
Our geographic team tags structural landmarks (building reference points, bridge anchors, infrastructure nodes), environmental features (road intersections, tree canopy centres, riverbank points), and navigation waypoints from satellite imagery, aerial photography, drone footage, and street-level panoramic imagery – all with GPS coordinate precision calibrated to imagery resolution.
GeoJSON, GPS-tagged point clouds, or custom JSON – matched to your mapping pipeline
Output formats include GeoJSON for mapping frameworks, GPS-tagged point cloud formats for LiDAR-camera fusion mapping, and custom JSON schemas for proprietary navigation systems. Your geographic intelligence pipeline receives landmark data in the exact schema it consumes – configured before the project begins, not adapted after delivery.
We provide landmark annotation across all keypoint-based AI applications, deployed as standalone projects or managed annotation pipelines:
Full-body keypoint annotation across all major pose schemas: COCO body pose (17 keypoints), COCO-WholeBody (133 keypoints covering body, face, hands, and feet), AI Challenger (14 keypoints), and MPII Human Pose (16 keypoints). Annotators follow anatomical reference conventions for each schema, placing keypoints at defined bony landmarks rather than approximate visual positions. Delivery in COCO keypoints JSON with visibility flags.
Facial keypoint annotation from sparse to dense schemas: 5-point minimal landmarks for face alignment, 68-point dlib (the facial analysis research standard), 98-point and 106-point schemas, and 468-point MediaPipe face mesh. Our facial team has schema-specific training on canonical placement conventions. Delivery in dlib pts format, MediaPipe JSON, COCO keypoints, or custom schemas. Applications include facial recognition, emotion detection, driver monitoring, and AR calibration.
21-keypoint-per-hand annotation following the MediaPipe hand schema with individual finger joint resolution. For two-hand interaction datasets (sign language, bimanual manipulation), we maintain consistent hand identity labeling across frames. Output in MediaPipe hand landmark JSON. Applications include sign language AI, AR/VR hand tracking, and robotic manipulation training.
Structural keypoint annotation for vehicle orientation and dimension estimation. We annotate headlight centres, wheel centres, mirror positions, roof corners, and bumper edges following autonomous vehicle perception conventions. Output in KITTI keypoint format, COCO keypoints JSON, or custom schema, enabling monocular 3D vehicle detection models to estimate pose and dimensions from single camera frames.
Anatomical keypoint annotation for clinical measurement and surgical planning AI. Our team annotates bone reference points for Cobb angle measurement, joint axis deviation assessment, and pre-surgical planning. Delivery in DICOM overlay, NIfTI, and custom JSON schemas. HIPAA-aligned data handling for all medical projects.
For domain-specific landmark requirements, we build custom keypoint ontologies from your specification, validate on a pilot batch of 500 to 1,000 images, and scale to production once accuracy thresholds are confirmed. Past custom schemas include industrial assembly reference points, agricultural plant growth points, and architectural deformation monitoring.

Annotating pre-recorded and live video stream of vehicles provided training data for machine learning models for a California based data analytics company helped managing traffic efficiently.
Read full Case Study »
The food images to be labelled and categorized so that the client could use them as training data for accurate interpretation of visual data through data annotation.
Read full Case Study »
Capture, validate and verify information on upcoming or existing construction projects from multi-lingual and multi-format online publications across Europe and USA.
Read full Case Study »
Keypoint placement on 17-point COCO skeleton, 133-point whole-body, and custom body schemas with OKS accuracy calibrated per joint. Used for sports biomechanics, rehabilitation monitoring, workplace safety, and action recognition AI.
Placement precision calibrated per anatomical point, not averaged across all 68 or 98 landmarks. Eye corners require 1-2 pixel accuracy at source resolution because face recognition models are sensitive to periocular geometry. We measure OKS per-point, not a single aggregate score.
Annotated facial datasets with Action Unit labels (AU1 inner brow raise, AU6 cheek raise, AU12 lip corner pull) alongside landmark coordinates for emotion recognition and facial AU classification training. Combined datasets reduce cost and time for emotion AI model development.
Combined bounding box and landmark annotation in a single dataset for applications that pair object detection with keypoint regression, formatted for two-stage or end-to-end architectures.
Facial landmark annotators trained in facial anatomy and schema-specific placement conventions. Geographic landmark annotators trained in satellite imagery interpretation and GPS coordinate precision. No general image annotators on specialist landmark tasks.





Landmark annotation places precise point markers at defined anatomical or structural locations, such as body joints, facial feature points, and hand joints. Unlike bounding box annotation, which captures only object location and size, landmark annotation captures spatial relationships between specific points. This is the training signal for pose estimation, facial analysis, and gesture recognition AI.
We support COCO body pose (17 keypoints), COCO-WholeBody (133 keypoints), AI Challenger (14 keypoints), dlib facial landmarks (68 points), MediaPipe face mesh (468 points), MediaPipe hand (21 keypoints per hand), MPII human pose (16 keypoints), OpenFace, DeepFace schemas, vehicle keypoints, animal pose schemas, anatomical landmarks for medical imaging, and fully custom schemas.
We follow the COCO visibility convention: 0 (not labeled), 1 (labeled at inferred position, not visible), or 2 (labeled and visible). Whether to annotate inferred positions is specified per-project in the annotation guideline. Body pose typically uses inferred positions (adjacent joints provide position priors); facial landmarks typically skip them (occlusion is too ambiguous). QA validation enforces compliance.
COCO keypoints JSON ([x, y, v] triples with visibility flags), MediaPipe JSON, dlib pts format, CSV coordinate tables, TensorFlow Pose format, and custom schemas. Facial landmarks are also delivered in raw CSV compatible with OpenFace and DeepFace frameworks.
Yes. We annotate vehicles (orientation estimation keypoints), animals (livestock and wildlife pose schemas), industrial parts (robotic assembly reference points), and architectural structures (deformation monitoring). All custom schemas are validated on a pilot batch before production.
Our primary metric is normalised point distance (NPD), measuring keypoint error as a proportion of object size for scale-independent accuracy comparison. We target 97%+ NPD accuracy, report per-keypoint scores at delivery, and re-annotate below-threshold keypoints at no charge. For body pose, we also report Object Keypoint Similarity (OKS), the COCO standard metric.
Pricing depends on schema complexity (keypoints per instance), dataset volume, and domain requirements (medical annotation requires clinical training). Every quote includes a free pilot batch of 500 to 1,000 images to evaluate quality before full-scale commitment.
Kickoff takes 3 to 5 business days from guideline approval. A 10,000-image COCO body pose project completes in 2 to 3 weeks; a 100,000-image WholeBody project in 8 to 12 weeks. Burst capacity available within 48 hours for urgent timelines.


Disclaimer: HitechDigital Solutions LLP and HabileData will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@habiledata.com.