Every AI model is only as reliable as the data it learns from. When training datasets contain mislabeled objects, inconsistent class boundaries, or annotation errors, models carry those failures into production - generating wrong predictions at scale. HabileData delivers data annotation services built around measurable quality: inter-annotator agreement (IAA) scores of 95%+ across image, video, text, and LiDAR data types, validated through a three-stage human QA workflow before any dataset leaves our team.
Request a free custom data annotation quote »
Most AI projects do not fail because of weak algorithms. They fail because the training data was never reliable enough to begin with.
At HabileData, our data annotation services are built around one principle: measurable quality before model training begins, not damage control after. Every project starts with a defined annotation schema, calibrated labeling guidelines, and inter-annotator agreement tracking across batches. Your ML team validates dataset consistency with actual metrics, not gut feel.
Measurable quality before training begins – not damage control after
Every project starts with a defined annotation schema, calibrated labeling guidelines, and inter-annotator agreement tracking across batches. Your ML team validates dataset consistency with actual metrics – not gut feel. Quality is measured before model training begins, so errors never compound into production failures.
Domain-trained annotators – not generalists working from a basic checklist
Our annotators understand the domain context of what they label – image, video, text, NLP, and LiDAR point cloud annotation. That depth separates training data that improves a model from data that quietly limits it. Medical annotators know anatomy. AV annotators handle occlusion. NLP annotators understand linguistic nuance.
Timelines you can depend on – backed by 30 years of delivery
When enterprises and AI startups outsource data annotation, they need timelines they can depend on. HabileData delivers – backed by a three-stage human QA framework, ISO-certified processes, and over 30 years of data services experience. When your model needs more data, we move – not you.
Security you can defend to stakeholders – ISO-certified and audit-ready
ISO-certified processes, AES-256 encrypted transfer, role-based access controls, and NDAs for every team member. HIPAA BAA and GDPR-aligned workflows available. Client retains 100% data ownership – always. Security your enterprise stakeholders can verify, not just a policy page on a website.
We provide annotation across all major data types and annotation techniques, deployed as individual services or as a managed end-to-end annotation pipeline:
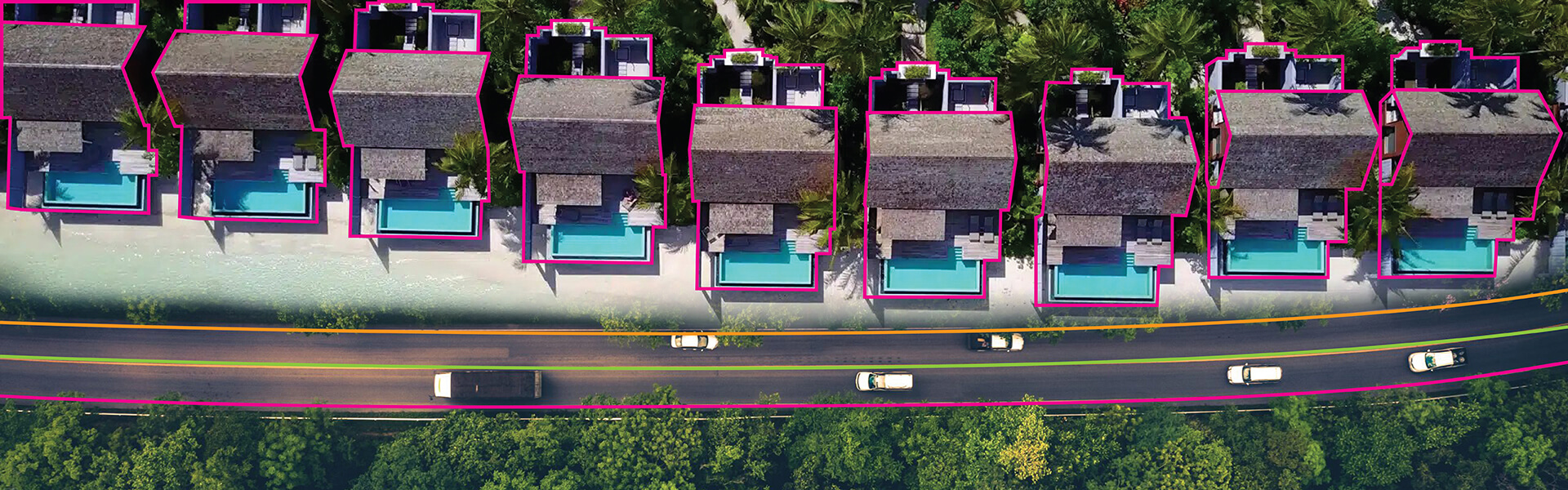
The broadest annotation category. Our image annotation team handles 2D object detection (bounding box), precise outline tracing (polygon), pixel-level class labelling (segmentation), structural point mapping (landmark), and sequential path annotation (polyline). We process 10,000+ images per day across concurrent projects.
Bounding box and polygon annotation maintained with consistent object IDs across frames. Object tracking through occlusions and camera cuts. Action recognition and temporal event segmentation. Activity classification for surveillance, sports analytics, and robotics training. Output: JSON with frame-indexed annotation arrays.
Named Entity Recognition (NER) tagging for person, organization, location, date, monetary value, and custom domain entities. Sentiment annotation (positive/negative/neutral) at sentence, paragraph, or document level. Intent classification for conversational AI. Relation extraction for knowledge graph construction. Cohen’s Kappa IAA target 90%+.
For AI models that process multiple data types simultaneously – image-text pairs for vision-language models, audio-video synchronization for speech recognition, sensor fusion data for autonomous systems. Maintains cross-modal alignment and temporal synchronization. Supports CLIP, GPT-4V, and Flamingo-style model architectures.

Annotating pre-recorded and live video stream of vehicles provided training data for machine learning models for a California based data analytics company helped managing traffic efficiently.
Read full Case Study »
The food images to be labelled and categorized so that the client could use them as training data for accurate interpretation of visual data through data annotation.
Read full Case Study »
Capture, validate and verify information on upcoming or existing construction projects from multi-lingual and multi-format online publications across Europe and USA.
Read full Case Study »
The true cost of in-house annotation includes recruiter salary, annotator wages, QA management, tool licenses, and infrastructure. HabileData’s offshore delivery model eliminates all of these – clients consistently achieve 60-70% cost reduction on annotation spend compared to equivalent internal capacity, without any reduction in output quality or IAA scores.
Our team of 300+ annotators processes 10,000+ images daily at standard throughput, with burst capacity available for high-volume campaigns. For text annotation, daily throughput reaches 500,000+ tokens. For video, we handle 50,000+ annotated frames per day. Clients who previously spent months on annotation backlogs typically reduce timelines by 60-75% in the first quarter.
Quality is not self-reported – it is measured. Every dataset delivery includes per-class IAA scores (Cohen’s Kappa for classification, IoU for segmentation, MOTA for video tracking). If a project’s IAA drops below the agreed threshold, the batch is re-annotated at no charge before delivery. Our standard thresholds: 95%+ IoU for bounding box, 92%+ for polygon, 0.92+ Kappa for NER.
AI training data requirements do not scale linearly — they spike. When a model iteration requires a larger dataset, when a new use case needs coverage, or when a production model underperforms on a class that needs more labeled examples, we scale within 48 hours. No hiring, no onboarding, no capacity ceiling that blocks your model release.
Inconsistent annotation is the primary cause of model failure. Every project starts with a written annotation guideline document that specifies class definitions, boundary rules, and edge case handling. Annotators are tested against the guideline before project start. All subsequent annotations are validated against it. This eliminates the interpretation drift that degrades dataset quality in long-running projects.
Our annotators are not generalists working from a basic tutorial. Each specialist is trained in domain-specific labeling guidelines, edge-case handling, and the nuances of their assigned industry. Medical annotators understand anatomical structures. AV annotators understand object occlusion. NLP annotators understand linguistic subtlety. This depth of expertise shows up directly in your model performance.
Data Review and Scope Assessment
We review your raw dataset for volume, format, quality, and edge-case distribution before any work begins.
Annotation Guideline Creation
We produce a formal annotation guideline document defining class taxonomy, boundary rules, inclusion/exclusion criteria, and edge case handling for every class in your ontology.
AI-Assisted Pre-Labeling
For image and video datasets, we apply AI-assisted pre-labeling to generate initial labels that annotators refine. This reduces annotation time by 40–60% without reducing accuracy.
Three-Stage Human QA Review
Stage 1: Primary annotator submits labels. Stage 2: Senior QA reviewer validates against guideline for every annotation. Stage 3: Automated geometric validation checks.
Dataset Delivery with IAA Report
Final datasets are delivered in your specified format (COCO JSON, Pascal VOC, YOLO TXT, custom schema) with an IAA report.
HabileData is tool-agnostic. We work with your preferred annotation platform or operate on our own proven internal tooling. We also support output in all standard formats so your annotated datasets integrate directly into your training pipeline without conversion overhead.
Our annotation teams have domain-specific expertise and trained ontologies for the following industries. Domain specialization means annotators understand the objects they are labeling — reducing edge-case errors and improving IAA on ambiguous classes.





Data annotation services transform raw, unstructured data into precisely labeled training datasets that AI and machine learning models can learn from. Without accurate annotation, even the most sophisticated algorithms produce unreliable outputs. Good annotation is what separates a model that performs in a lab from one that holds up in production. At HabileData, every annotation decision is made with your model’s real-world performance in mind.
The terms are often used interchangeably, but there is a distinction. Data labeling typically refers to assigning a single categorical tag or class to a data point. Data annotation is broader and includes adding contextual metadata, bounding regions, segmentation boundaries, relationships, and attributes. In practice, most modern AI projects require annotation rather than simple labeling, and HabileData handles both within a unified workflow.
In-house annotation struggles with scale, consistency, and cost. Recruiting trained annotators takes months. Building quality assurance processes takes longer. Managing annotation teams across projects takes ongoing resources. Outsourcing to HabileData gives you immediate access to experienced annotation specialists, proven QA workflows, and faster turnaround — at a fraction of the cost of equivalent internal capacity.
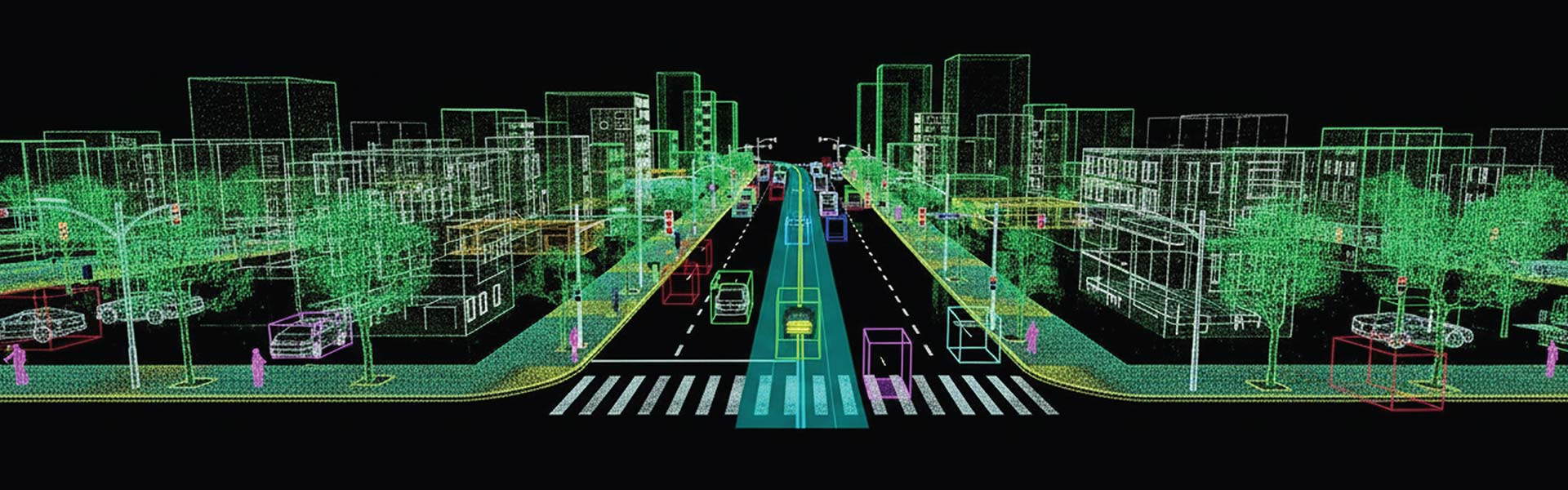
HabileData annotates image data, video data, text and NLP datasets, audio and speech data, LiDAR point clouds, and multimodal datasets combining multiple data types. We handle everything from standard object detection tasks to complex multi-class semantic segmentation, multilingual text annotation, and sensor fusion labeling for autonomous systems.
We use a multi-layer QA approach. AI-assisted pre-labeling accelerates throughput, followed by expert human-in-the-loop review, multi-tier quality audits, inter-annotator agreement tracking, and statistical sampling. Our process is designed to catch errors at every stage, not just at delivery. Clients receive accuracy reports and QA documentation with every dataset.
Yes. Our distributed annotation teams, scalable infrastructure, and batch processing workflows are built for high-volume projects. We have supported annotation programs ranging from targeted pilots to multi-million-data-point enterprise programs across autonomous vehicle, healthcare, and NLP verticals. Whatever your scale, we can ramp up quickly without compromising quality.
Security is non-negotiable for us. HabileData operates under ISO-certified processes with strict access controls, encrypted data transfer channels, role-based permissions, and comprehensive NDAs. Sensitive and proprietary client data is handled in controlled environments by cleared team members only. We are equipped to support healthcare data, financial documents, and defense-adjacent applications with appropriate data handling protocols.
We support more than 30 annotation techniques including bounding box, polygon, polyline, semantic segmentation, instance segmentation, keypoint annotation, LiDAR point cloud labeling, 3D cuboid annotation, named entity recognition, sentiment tagging, intent classification, and multimodal annotation. If your use case has specific technique requirements, our team will advise on the best approach.
Most projects enter an onboarding and pilot phase within a few days of initial engagement. We use the pilot batch to validate quality alignment before scaling to full production volume. This means you get confidence early and momentum quickly, without the months of setup that in-house annotation requires.
Yes. Many of our client relationships are long-term partnerships where we provide continuous annotation support as models are retrained, new data types are introduced, or edge cases surface in production. We offer flexible engagement models that scale with your AI development roadmap.

Disclaimer: HitechDigital Solutions LLP and HabileData will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@habiledata.com.