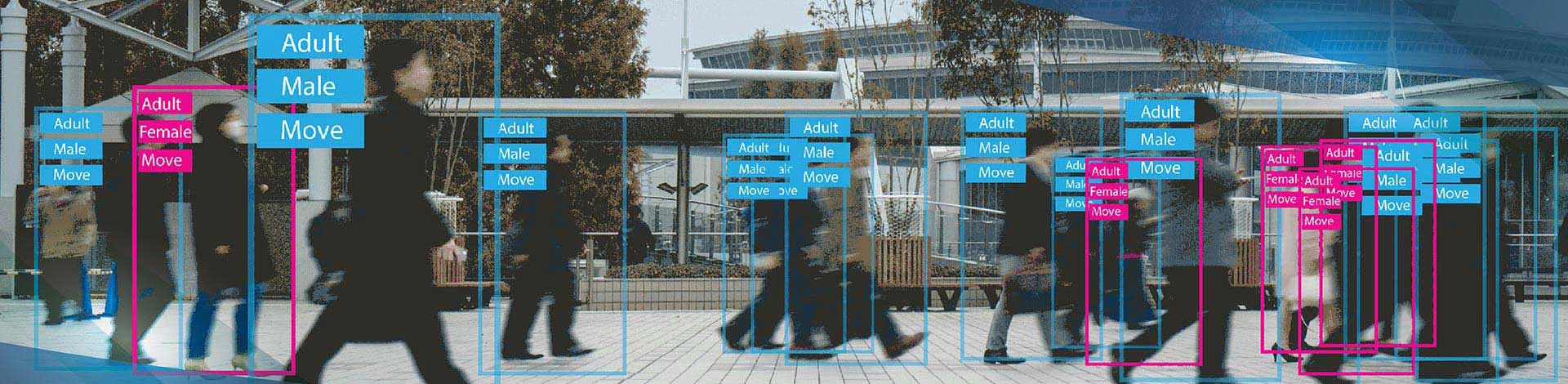
Our semantic segmentation services assign a class label to every pixel in a scene - not just objects, but road surface, sky, background, and partial boundaries. This pixel-level precision enables AI models to understand scene composition with the granularity that bounding box annotation cannot provide. HabileData achieves 92%+ mean pixel IoU across standard class sets using a three-stage QA process that includes automated mask coverage validation. We annotate in JPEG, PNG, TIFF, and DICOM formats, delivering in COCO panoptic, Pascal VOC, Cityscapes JSON, or custom schema.
Get started with a free trial »
The real challenge in semantic segmentation is not drawing pixel boundaries. It is drawing them consistently at scale across every annotator.
HabileData’s semantic segmentation services are built on one principle: consistency is an engineering problem, not a talent problem. Every project begins with written class boundary rules, edge case protocols, and occlusion decisions documented before a pixel is labeled. Annotators are calibrated on your actual data with mIoU measured per batch.
Consistency engineered before a single pixel is labeled
Written class boundary rules, edge case protocols, and occlusion decisions are documented before annotation begins. Annotators are calibrated on your actual data and inter-annotator agreement is measured per batch using mIoU. No batch leaves our pipeline until it meets the agreed accuracy threshold.
SAM pre-labeling for speed – human annotators for every boundary
Segment Anything Model (SAM) pre-labeling on structurally stable regions accelerates throughput by 40–60%. Human annotators handle all boundary regions, fine-detail classes, and moving objects that AI pre-labeling cannot reliably produce. The result is a pixel-level dataset that is both fast to deliver and genuinely accurate.
Semantic, instance, and panoptic – in PNG masks, COCO JSON, or custom schema
We support semantic, instance, and panoptic segmentation across autonomous vehicles, medical imaging, geospatial analysis, and precision agriculture. Output delivered in PNG semantic masks, COCO panoptic JSON, or any custom schema your ML framework requires – configured before the project starts, not after.
Annotation consistency is an engineering problem – not a talent problem
Without project-specific guidelines, ten annotators produce ten different segmentation maps for the same image and your model trains on inconsistency. We treat consistency as an engineering problem: calibrated annotators, written protocols, and mIoU-gated delivery eliminate the variance that silently degrades model performance.
We provide three levels of segmentation annotation, each with technique-specific tooling, accuracy benchmarks, and output format configuration.
We assign a unique instance ID to each individual object in addition to its class label. Every car, person, and instrument in the scene is labeled and distinguished from every other member of the same class. Used to train instance segmentation models (Mask R-CNN, SOLOv2, QueryInst) and as a precursor to multi-object tracking datasets.
Every pixel in the image is classified to a semantic class (road, sky, building, vegetation), and every countable object (person, vehicle, bicycle) also receives a unique instance ID. The most complete form of scene annotation, required for autonomous vehicle models that need full spatial awareness at the pixel level.
Standard semantic segmentation assigns every pixel a class label without instance distinction. The output is a dense pixel-level classification map – every pixel belonging to a defined class in your ontology. Used for scene understanding, land use mapping, medical tissue classification, and any application where class-level pixel coverage matters more than individual object count.
Frame-by-frame semantic segmentation across video sequences, with temporal consistency validation to ensure class boundaries do not drift between adjacent frames on objects that have not changed. Essential for autonomous vehicle training data and surveillance AI. We apply CVAT interpolation for smooth transitions and run temporal consistency as a dedicated QA step separate from frame-level accuracy checks.
This is the question ML engineers most commonly ask when scoping a new computer vision annotation project, and getting it wrong wastes months of training time.

Every segmentation batch includes per-class mean pixel IoU scores. If any class falls below the agreed threshold, the class is re-annotated before delivery. Medical imaging segmentation is validated by clinical domain reviewers.
SAM, Labelbox segment anything, and V7 Darwin AI brush reduce segmentation annotation time by 60–80% on clearly bounded objects. For complex boundary scenarios (tumour margins, agricultural field edges), human annotation with AI assistance maintains quality.
Complex multi-class scenes (urban traffic, medical scans, agricultural aerial imagery) require annotators who understand the domain well enough to apply class boundary rules consistently across thousands of images. Our segmentation teams are domain-matched.
mIoU is calculated and documented per delivery batch. You receive a QA report alongside the annotated data showing per-class IoU scores, overall mIoU, error frequency by class, and notes on any edge cases where the boundary rule required interpretation. This gives your training pipeline an objective quality signal, not a vendor promise.
Frame-by-frame segmentation introduces a failure mode that image-only projects do not have: boundary drift between adjacent frames on objects that have not moved. We run temporal consistency as a dedicated QA step separate from frame-level accuracy audits, specifically to catch this failure mode before it enters your training data.
Semantic segmentation is required in any application where the AI model must understand what occupies every part of a scene, not just where specific objects are approximately located.





Semantic segmentation assigns a class label to every pixel in an image, producing a dense classification map of the entire scene. A model needs it when knowing the approximate location of objects (bounding box) is not enough – when the task requires understanding exactly what occupies every part of the frame. Autonomous vehicle perception, medical image analysis, land use classification, and scene understanding AI all require semantic segmentation because the model must make decisions at boundary level, not just object detection level.
Our SLA target is 0.84+ mean Intersection over Union (mIoU) measured per delivery batch. mIoU is the standard evaluation metric for semantic segmentation – it measures the overlap between the predicted and ground-truth class regions for each class, averaged across all classes. We calculate and report mIoU per class in every delivery document. If a batch falls below the agreed threshold, it returns to production for correction before delivery.
We deliver per-frame PNG semantic masks with the associated class colour map file (compatible with PyTorch, TensorFlow, Keras, and MMSegmentation), COCO panoptic JSON for panoptic and instance segmentation tasks (compatible with Detectron2 and MMDetection), and custom colour-coded mask formats for proprietary ML pipelines. If your pipeline uses a different format, provide the specification and we configure output before the project begins.
Yes. Our medical imaging segmentation team uses V7 Darwin with DICOM format support, HIPAA-aligned access controls, and patient metadata removal from DICOM files before annotation begins. Annotators working on medical imaging projects are trained in clinical terminology and anatomy-specific boundary rules. IAA targets for medical segmentation are calibrated per project with the client’s clinical team – typically DSC 0.88+ for standard organ segmentation tasks.
Standard semantic segmentation on 10,000 images with a 5 to 8 class ontology and no complex fine-detail classes typically takes 12 to 18 business days with a team of 20 annotators, including calibration, pilot batch, full production, and QA. Medical imaging and fine-detail segmentation (surgical footage, satellite imagery at high resolution) takes longer and is scoped individually. We provide a timeline estimate after reviewing a sample of your dataset.
Semantic segmentation assigns a class label to every pixel but does not distinguish between individual instances of the same class – all cars in the image are labeled ‘car’. Instance segmentation assigns both a class label and a unique instance ID to each individual object, so ‘car_1’, ‘car_2’, and ‘car_3’ are all distinguished from each other. Use semantic segmentation when class coverage matters; use instance segmentation when you need to count or track individual objects. Panoptic segmentation combines both.


Disclaimer: HitechDigital Solutions LLP and HabileData will never ask for money or commission to offer jobs or projects. In the event you are contacted by any person with job offer in our companies, please reach out to us at info@habiledata.com.