
Data cleaning always attracts questions about how, why and what’s the best form of B2B data cleansing. Coherent plan backed by technology solutions and executed by data cleansing specialists prove to be force multipliers that arm aggregators with high quality data to make profitable growth.
Contents
Maintaining data quality is a serious task for B2B data aggregators, and they spend a significant chunk of their best resources to keep contact lists, profiles, product, customer, sales, demographics, and other data clean, accurate, and updated.
According to HBR, 47% of newly created data records carry at least one major error that affects work. And we are talking here of the fresh data in databases, not just old records that everyone knows need cleansing and enrichment.
High-quality data gathered from different sources requires validation & makes data cleansing a mandatory and ongoing operation for data aggregators.
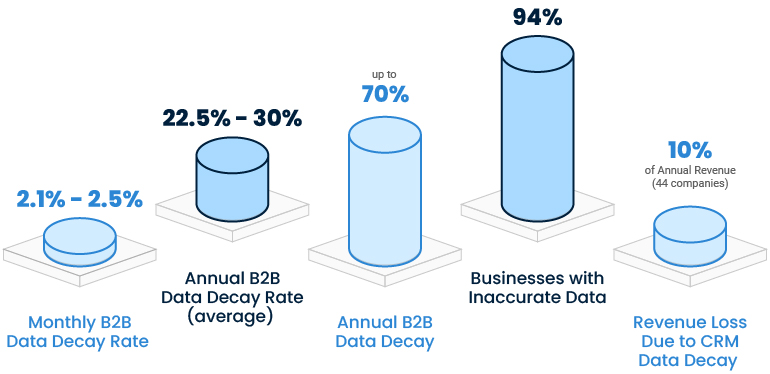
Challenges in maintaining B2B database quality
Dirty data is a serious problem for businesses. Poor data quality costs the US economy approximately $3.1 trillion annually. Garbage in, garbage out is what it is. The challenges of B2B data aggregators have also multiplied with the entire digital world backed by data shifting to real-time data streams. Combining datasets from multiple sources is critical when the quality of the output affects business revenues. The only way to address this is to identify erroneous data and take steps to rectify it.
10 common issues with incoming real-time data from disparate sources

Read also: How is data quality affecting your organization?
8 expert B2B data cleansing tips
Dirty data, data errors, data in varied and inconsistent formats, and similar challenges are inevitable in data aggregation. Cleaning the data and making it usable for clients requires putting in place B2B data cleansing best practices before you initiate the data cleansing process.
To ensure high-quality B2B databases, implement these 8 expert data cleansing tips.
Tip 1: Start with a Data Quality Plan

With 27% of data aggregators uncertain of their database accuracy, it is critical to chart out a data quality plan to establish a realistic baseline for data hygiene. It is important to have a roadmap because without a plan, data errors will always remain, and you waste resources on inconsistent efforts.
You need to create a documented plan that defines KPIs, cleansing frequency, error types, and validation processes. Here are tips to create a data cleansing plan to maintain the quality of your B2B database:
- Establish Data Quality Standards – Determine what constitutes “good” data for your specific B2B needs.
- Identify Key Performance Indicators (KPIs) – Define metrics like error rates, completion rates, and response times to track progress.
- Understand Stakeholder Needs – Engage with data consumers to understand their expectations and requirements.
- Data Audits – Regularly audit your data against established standards to pinpoint areas needing improvement.
- Data Source Assessment – Determine where your data originates and assess the reliability of each source.
- Data Cleansing Workflow – Establish a repeatable process for cleaning data.
- Automation – Utilize automation tools and scripts to streamline data cleansing tasks and reduce manual effort.
- Data Enrichment – Enhance data with information from reliable sources to improve its completeness and accuracy.
- Data Governance – Implement policies and procedures for data collection, storage, and cleansing to ensure consistency and accountability.
- Data Validation – Implement validation checks to ensure data meets specific criteria during entry and update.
- Regular Audits – Conduct periodic audits to verify data accuracy, completeness, and consistency against defined standards.
A messy database is costing you leads and conversions.
It’s time to implement smart data cleansing strategies.
Get a free consultation »Tip 2: Use Automation to Clean as You Collect

Validation done later or using manual data entry has multiple issues. Bad data will already be in your database before you realise it, and then cleansing can be a task. Fixing errors later often gets more expensive and complicated. Use of automation, like AI/RPA tools at the point of entry, is recommended.
Checking the problem at the source, before it gets entry to the aggregator database, is the first critical step to take. 309,000 records were entered within 45 days to deliver a robust, drilled-down, and easy-to-access database to the California Bar Council with the help of technology-driven data entry.
The shift to real-time data has also made automated data cleansing essential. Except in cases of outliers, where considered decision needs to be taken, real-time data entry depends on automated cleansing with the use of RPA, AI, and machine learning.
Here are a few tips for effective use of automation in data collection:
- Identify Repetitive Tasks – Look for tasks that involve manual data entry, repetitive data manipulation, or data extraction.
- Be Clear on Objective – Define what you look to achieve from automation, like efficiency, quicker job, or fewer errors.
- Choose the Right Tools – Select automation tools that align with your specific requirements.
- Implement Automation – Start with automating specific tasks, ensuring a smooth transition and less disruption to existing processes.
- Test and Refine – Thoroughly test the automated processes to identify and rectify any issues or errors.
- Scale Up Gradually – Expand automation to other areas gradually, go step by step.
- Continuous Monitoring – Monitor the performance of your automated data collection processes, tracking key metrics like speed, accuracy, and cost savings.
- Detect errors – For real-time data, monitor the incoming data streams, detect errors, and correct issues using automation.
- Stay Updated – Keep abreast of emerging trends and technologies in data automation to ensure your processes remain efficient.
Read also: 4 checkpoints to improve the quality of your data
Tip 3: Identify and Remove Duplicate Records

Data comes from multiple sources, and there are chances of duplicates or bad data in any dataset. Duplicates result in poor segmentation, wasted outreach, and skewed analytics.
The data is clustered by the process of merge/purge, which stores the data in one place, removing redundant records. Often duplicate records also contain unique data, like one may have an email address of the customer, while the other may have their cell number. So duplicate data can’t be removed arbitrarily. The solution lies in performing regular deduplication using fuzzy logic and data matching rules.
Here are tips to manage duplicate records:
- Define Duplicates – Duplicates can be identified if your database has unique IDs (e.g., customer ID, account number).
- Fuzzy Matching – For data with slight variations, fuzzy matching techniques can help identify potential duplicates.
- Identify Duplicates – Use tools and techniques like SQL queries, data cleaning software, or even manual review to pinpoint duplicates.
- Apply Data Validation – Implement data validation rules to prevent future duplicates from being entered into the database.
- Merge Records – Choose the removal method carefully. Merging or updating records might be preferred over deletion in some cases.
- Merge databases – Merge different databases from disparate sources like Excel, SQL server, MySQL, etc., into a common structure.
- Use Advanced Techniques – Advanced data matching techniques in the merge/purge process, ensure that only one record is generated, retaining all required information, and removing duplicates.
Tip 4: Standardize Data Entry Across Systems
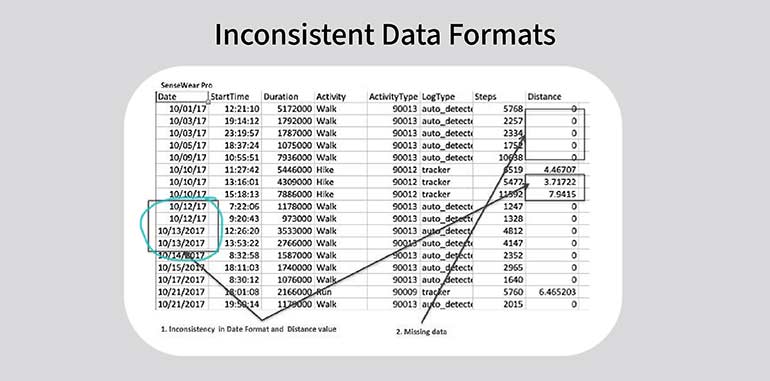
Inconsistent formats (e.g., job titles, phone numbers, dates) across sources break search, segmentation, and downstream analytics. To handle this issue, one needs to define a master format and ensure that it is applied across the entire database. It can be done using validation rules and SOPs. Here are a few tips to ensure uniform format.
- Define Clear Standards – Develop a comprehensive data dictionary that outlines consistent formats.
- Define Responsibilities – Clearly define who is responsible for data entry, validation, and maintenance within each system.
- Enforce Data Quality Rules – Implement rules and validation checks to ensure data adheres to the defined standards at the point of entry.
- Centralized Database – Use a central repository or master data management system to store and manage all B2B data.
- Automate Form Filling – Implement tools that automatically populate forms with pre-defined data, minimizing manual input and errors.
- Automate Data Validation – Use automated checks to identify and flag inconsistencies, errors, or missing information during data entry.
- Create SOPs – Create and share SOPs with the internal and external teams, ensuring all follow the same style.
- Train team – Periodic training of the team on data standards and tools helps keep the team abreast of the standards.
Tip 5: Fill Missing Fields with Smart Enrichment
One of the key challenges in data cleansing is handling missing values that distort analytic findings. Incomplete profiles limit personalization and targeting. Gaps in firmographic or contact data reduce campaign effectiveness and sales conversions. The solution lies in enriching the database using external sources or machine learning based imputation.
Here are a few tips to make your job easier –
- Define Specific Fields – Determine which missing fields need to be enriched and the specific information required for each.
- Choose Enrichment Sources – Explore internally the existing data and third-party data providers that specialize in enriching specific data types.
- Assess Data Quality – Assess the quality, accuracy, and completeness of data from potential sources before integrating them.
- Identifiers – Utilize common identifiers (e.g., email, phone number, customer ID) to link records between your dataset and the enrichment source.
- Probabilistic Matching – Employ algorithms to estimate the likelihood of a match when exact matches are not available.
- Consider Fuzzy Matching – Use techniques that allow for slight variations in matching criteria to account for inconsistencies in data formats.
- Explore Imputation Techniques – Replace missing values with estimated values using statistical methods or machine learning models.
- Use AI Power – Leverage AI and machine learning models to predict missing values based on existing patterns and relationships within the data.
Tip 6: Detect and Manage Outliers

Outliers create issues with analysis and machine learning outcomes. They can mask real trends or produce false insights, and therefore, they form a special case in data cleansing.
Detecting outliers, analysing them, and processing them first is required to prepare datasets for machine learning models, and consequent real-time or near-real-time automated data cleansing. Processing outliers and enriching 17 million+ hospitality records drives efficiencies in marketing campaigns for a hospitality data aggregator company.
Here are a few tips on handling outliers:
- Detection Methods – Outliers are usually detected through data visualization methods and methods like Z-Score (parametric), linear regression, proximity-based models, and others. One can use statistical or visual methods to detect and flag anomalies for review.
- Mild Outliers – Identify mild outliers, and segment and analyse them thoroughly.
- Extreme Values – These can be removed by data trimming. The usual practice is to decide whether changing the outlier value to one that matches the dataset will help or hurt cleansing, and then do it.
- Removal – If outliers are due to errors, removing them can improve analysis.
- Transformation – Applying transformations like logarithms or square roots can reduce the impact of outliers.
- Winsorization – Replace outlier values with the nearest non-outlier value.
- Robust Algorithms – Use algorithms less sensitive to outliers, like decision trees or random forests.
- Imputation – Replace outliers with a more central value, like the median.
- Capping/Clipping – Set upper or lower limits on values to constrain outliers.
Tip 7: Monitor Data Health Regularly

Bad data leads to high bounce, low clicks, and even lower conversions. Data once cleansed can become obsolete without a monitoring system. It is important to implement scheduled audits and automated alerts for decayed or invalid data.
Invest your time and efforts in automated systems that de-duplicate, validate, verify, enrich, and append your data.
- Use Technology – Technology empowered systems sift through large volumes of data using algorithms to detect irregularities and bad data.
- Set Regular Processes – Regular data de-duplication, validation, verification, and enrichment need to be done, as even good data goes bad.
- Identify Critical Data Points – Determine the most important data elements for your business and define what constitutes healthy data for those elements.
- Establish Data Quality Metrics – Define metrics for accuracy, completeness, consistency, timeliness, and relevance of data.
- Automated Processes – Implement automated checks to validate data against predefined rules and identify potential issues early.
- Set up Alerts – Configure alerts to notify you when data quality thresholds are breached or when anomalies are detected.
- Develop Dashboards – Create dashboards and reports that provide a clear overview of data quality trends and performance.
- Data Audits – Perform regular audits of data quality to identify any discrepancies or inconsistencies.
Tip 8: Align Sales and Marketing Feedback

Frontline teams often work with outdated or inaccurate data but have no way to report issues. Creating a feedback loop for sales/marketing to flag and suggest updates to data is a great solution.
Here’s a list of actionable tips:
- Foster Open Communication & Collaboration – Schedule regular meetings, encourage collaboration on projects, and create opportunities for teams to provide feedback.
- Define Shared Goals and Metrics – Agree on shared Key Performance Indicators (KPIs) that reflect overall business goals.
- Implement a Robust Feedback Loop – Gather feedback on the effectiveness of marketing content from sales reps, ensuring it aligns with their needs and resonates with potential customers.
- Utilize Technology to Facilitate Alignment – Implement a Customer Relationship Management (CRM) system that integrates sales and marketing data to provide a single source of truth for customer information.
- Do Relevance Analysis – This helps turn data into useful and actionable information. It helps get away with obsolete data.
Read also: 5 step process to clean bad sales data.
Clean data is the future of B2B
The future of B2B data management is all about hyper automation. With the growth of AI and ML tools, the focus of data cleansing has also changed. The aim now is to develop and deploy robust data cleansing processes that can prevent questionable data from entering the system whereas cleansing and validation are a continuous process.
Consult B2B data cleansing companies, invest in automation and technology-enabled tools to get the perfectly reliable data. Hiring a B2B data cleansing company with excellent technological infrastructure and reputation to assist you in all data cleaning requirements will prove to be a smart move.
Conclusion
Two things ring true when dealing with the complexity of handling real-time data today. The first is that real-time data aggregation is full of challenges, and the second is that there are enough advanced tools in the market that can overcome these challenges when used by B2B data cleansing experts.
There is virtually an arms race in managing B2B databases with pressure to acquire as much data as possible; but disorganised, inaccurate and unstructured data will lead to data accidents and generate false leads. Data quality needs to be optimized and properly validated and structured with contextual relevance, or big data will overwhelm and remain ineffective. Technology solutions and data experts provide the way out.
Even fresh data can be flawed.
Let us help you detect and fix issues—before they impact your business.
Speak with our data experts »


Snehal Joshi , Head of Business Process Management at HabileData, leads a 500-member team of data professionals, having successfully delivered 500+ projects across B2B data aggregation, real estate, ecommerce, and manufacturing. His expertise spans data hygiene strategy, workflow automation, database management, and process optimization - making him a trusted voice on data quality and operational excellence for enterprises worldwide. 🔗Connect with Snehal on LinkedIn


