
Property listing issues pull down both buyer trust and MLS platform performance. This is why MLS services need to be aware of the 5 major real estate listing problems and their solutions.
Contents
- How much does bad property listing data actually cost
- List of challenges
- Problem 1: Incomplete property data from fragmented sources
- Problem 2: Inaccurate, duplicate, and inconsistent property listing data
- Problem 3: Expired, stale, and withdrawn listings polluting your database
- Problem 4: Low-quality visual data reducing listing engagement and conversion
- Problem 5: Scaling property listing management across high-volume databases
- How automation and AI are redefining property listing management
- Conclusion
- FAQ
Five types of recurring data issues plague property listing site credibility and consumer interaction: incorrect records; inaccurate property data or misleading data; “ghost” listings; poorly formatted and visually presented content; and unmanageable workflow operations that cannot be scaled. While all real estate listing problems can be resolved, and as long as they are resolved at the source and not merely fixed at the surface. But resolving property listing issues will require a process that starts at the intake stage of the data stream rather than trying to fix errors downstream.
MLS systems and real estate data aggregators collect property information from many different sources – including MLS feed sources; third-party application programming interfaces (APIs), local portal providers, agent submissions, and manually entered data.
When you collect this amount of data on a large scale, the quality of the data quickly deteriorates. KPMG reports that 66% of real estate firms have stated that data strategy impacts their business decision-making. These effects are tangible: increased bounce rate, loss of brokers who subscribe to services, decreased search rankings, and loss of transaction revenue.
How much does bad property listing data actually cost
Poor property listing database data is a tech issue but has actual dollar value. IBM estimates that poor data quality costs US businesses $3.1 trillion annually. The cost of poor quality data is quantifiable in all aspects of the listing stack. A single incorrect entry (one that needs to be manually identified, investigated and corrected) could take up 30 to 45 minutes of a data team’s time. Add this cost to a database, receiving thousands of entries a week and the expense will quickly add up.
In addition to the financial cost, there is also an effect on the number of failed contracts or delayed closing due to inaccurate pricing. Both delays have affected brokers’ trust in the platforms providing the data.
Duplicate listings also affect the platform’s credibility. Studies report that those who experience duplicate or conflicting data are much more likely to stop their search. Stale and expired listings continue to make the problem worse for SEO purposes. Search engines crawl high numbers of dead listing URL and give lower priority to domain crawl budget for active listing URLs.
Each of these costs result from 5 different, repeatable failure areas for data operation in property listings, each with its own unique root cause and solution.
List of challenges
Below is a description of the different types of property listing issues, where each type of issue came from, what the business impact of the issues are and an operational solution that will fix each of the issues at their root cause.
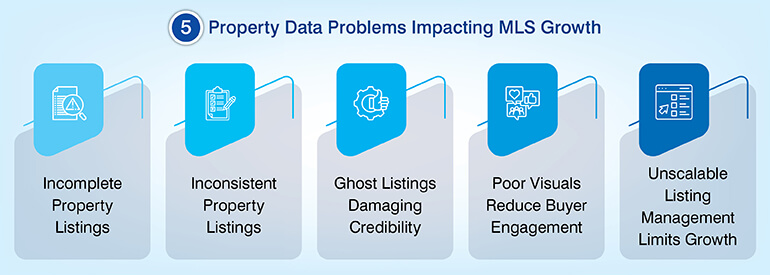
The following sections break down each problem, its root cause, associated business cost, and the operational fix that resolves it at the pipeline level.
Problem 1: Incomplete property data from fragmented sources
There are no individual data resources that provide complete listing information for either globally or nationally. There are many various data resources aggregators can draw upon including MLS feeds, local/Regional portals, agent submitted listings, and third-party structured and unstructured databases that may have different field schemas, update frequency and coverage issues. As a result, there is a database that has a lot of partial records.
The three most common reasons listings are incomplete
- Non-standardized formats among regional MLS providers lead to mapping issues when ingesting field names.
- Inconsistent update schedules from smaller or legacy data sources leads to stale records in active databases.
- Missing Fields (specifically, Amenities, Zoning Designations, and Geo-Coordinates) in third party data sources that do not enforce a data schema.
The business cost adds up quickly. Thin listings negatively affect time-on-listing metrics which algorithms use to rank listings. Fewer indexed listing pages negatively affect domain level search engine optimization (SEO). Broker-facing MLS platforms with incomplete records will also be perceived as lower quality data sources and therefore accelerate churn.
Multi-Source concurrent data collection strategy
Concurrent data collection is an approach that utilizes multiple data collection methods at the same time. It is not a solution, but rather a pipeline architecture that corresponds with the data collection method to the data source. Here’s a quick reference to leading data collection methods:
| Collection Method | Best For | Key Limitation |
|---|---|---|
| Custom APIs | Structured source data, real-time feeds | Requires source API availability |
| Scheduled Crawlers | Non-API MLS sites, unstructured sources | Vulnerable to anti-scraping policies |
| Manual Keying + Indexing Workflows | Legacy data, PDFs, offline records | Cost-prohibitive at scale |
Real-World Result
A real estate portal built a comprehensive residential and commercial property database, with significant improvement in client satisfaction and platform credibility. One of the leading real estate data collection companies deployed scheduled bots and crawlers to collect data from 1,350+ Multi-Listing Sites at regular intervals.
Need complete, current listing data across MLS sources?
Explore our services »Problem 2: Inaccurate, duplicate, and inconsistent property listing data
The term “bad data” is more than simply an issue related to formatting in a property listing database. Bad data has five distinct formats: incorrect contact information, incorrect property classifications (residential listings recorded as commercial listings), duplicate or altered images, inconsistent price fields, and unauthorized or illegal property description content.
According to IBM, bad data costs U.S. businesses approximately $5 million each year across all business sectors. The impact of bad data on property listing platforms is also quantifiable; mis-classification results in irrelevant buyer inquiries, increased support cost, and a damaged trust score with broker subscribers tracking lead quality.
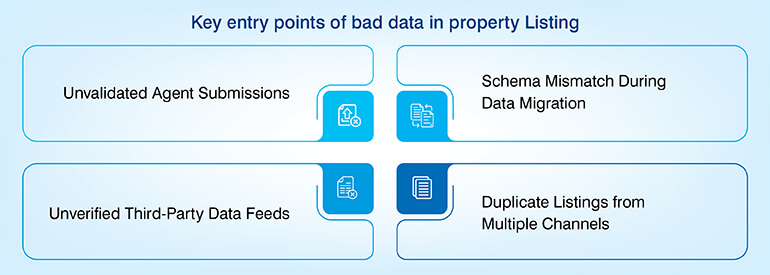
The four primary entry points where bad data is introduced to listing databases include:
- Agents submitting their own property listing information using unvalidated self-submission forms with no enforcement of mandatory fields
- Migration of data between platforms without normalization of the schema – large-scale data is migrated with values in the wrong column
- Feeds by third party data aggregation platforms without a documented service level agreement (SLA) regarding the quality of the data
- Multiple submissions of the same property by different channels resulting in duplicate property listings
Over 25 years of providing real estate data management solutions, the most preventable type of bad data they encountered is “unqualified acceptance of automated third party data feeds”, says an experienced data service provider. One feed with a missing or broken field mapping can create tens of thousands of records that will be contaminated prior to the error becoming apparent.
Automated data cleansing and rule-based validation workflows
A multi-layer validation architecture is the solution to the problem: a series of three sequential validation processes that capture different types of real estate listing errors prior to entering the live database.
- Layer 1 – Sampling-based Input Validation: As soon as incoming data is ingested into the system, it is split into batches. The validation process includes the following format checks, range validation, and completeness scoring performed on each batch. Any records that fall below the completeness threshold are identified and quarantined prior to them being entered into the live database.
- Layer 2 – Cross-validation of Multiple Channels: Owner records, contact details, property characteristics, and other legal identifiers are validated against independent secondary sources. This cross-validation process identifies errors that would not be detected through a single-source validation process – especially for owner data and legal compliance fields.
- Layer 3 – Rules-Based Attribute Classification: IF/THEN logic is used to validate the dependencies of linked field attributes.
Examples of rule include: If the property_type field equals ‘condo,’ the HOA_fee field is required. If the asking_price field is greater than $2M, a minimum image count threshold applies to the property listing. The rules help to prevent misclassification errors that could occur due to a format check alone.
For platforms that receive high levels of data from various inbound sources, data cleaning and validation services at the ingestion layer are not discretionary; they are the first line of defense against database-level quality degradation.
Real-World Result
A US-based real estate aggregator successfully reduced errors and improved buyer-facing data quality across the platform’s search results by deploying a multi-level quality control and audit framework to validate 650,000+ property records every month.
Problem 3: Expired, stale, and withdrawn listings polluting your database
Active listing durations are not fixed by time; a listing may be active for a minimum of 70 days or up to three years based upon seller actions, MLS policies, and frequency of relisting. When the originating MLS does not update the aggregator’s database regarding the status of a listing as “withdrawn” or “sold,” then the listing will continue to appear as an active search result which we refer to as a ghost listing.
The damage to the credibility of the platform is both direct and additive. Inquiries made by buyers on ghost listings will lead to the buyer losing confidence in the platform and thus will never return. Broker subscribers who receive leads on ghost listings will either track them down and find out that the property has been sold and/or withdraw their services due to complaints and churn.
The high volume of 404 responses or redirects on expired listing URLs will also negatively affect the crawl health for search engines and subsequently reduce crawl priority across the entire domain.
Ghost listings are not simply a data issue – but rather a credibility issue with respect to the platform reputation, which cannot be solved through improved user interface design downstream.
The HabileData 4-point listing verification protocol
Continuous and structured listing verification process required to eliminate ghost listings. To eliminate ghost listings, a structured listing verification process must run continuously not when needed using a defined protocol.
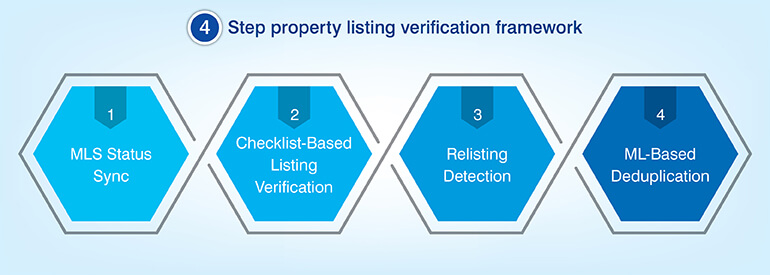
Continuous listing verification and ML-based deduplication
- MLS Status Sync: Defined periodic intervals of data pull from MLS feeds to determine if there have been any changes to the listing status e.g., active, pending, sold, or withdrawn. All changes trigger automatic updates to the database.
- Listing Checklist-Based Verification: Property checklist verifies all information contained within each record to ensure accurate data exists i.e., property status, legal standing, agent assigned, etc. If a record is determined to need a new listing, the checklist provides a method to generate a new listing.
- Relisting Detection: This process determines when a property has been previously withdrawn and then placed back into the marketplace as a new listing eliminating duplicate active records for the same property.
- ML-Based Deduplication: This process utilizes fuzzy logic to match similar records containing different formats for addresses, names of agents, property IDs, etc. identifying duplicate records that would otherwise be missed using exact string comparison.
Step 1: MLS Status Sync
Process Actions
- Periodic MLS data pulls
- Status change detection
- Active/pending/sold checks
- Withdrawn listing flags
- Automatic database updates
Operational Detail
- Defined pull intervals
- Real-time status sync
- Feed-triggered updates
- Listing state tracking
- Change event logging
Step 2: Checklist-Based Verification
Process Actions
- Record-level checklist review
- Property status confirmed
- Legal standing verified
- Agent assignment checked
- New listing generation
Operational Detail
- Field-by-field validation
- Compliance status check
- Assigned agent match
- Relisting trigger detected
- Checklist-driven workflow
Step 3: Relisting Detection
Process Actions
- Withdrawal history checked
- Re-entry to market flagged
- New listing ID matched
- Duplicate records blocked
- Active record deduped
Operational Detail
- Prior withdrawal lookup
- Same property cross-match
- Dual active record prevention
- Listing ID reconciliation
- Market re-entry tracking
Step 4: ML-Based Deduplication
Process Actions
- Fuzzy logic matching
- Address variant detection
- Agent name matching
- Property ID reconciliation
- Near-duplicate identification
Operational Detail
- Beyond exact-string match
- Format-agnostic comparison
- Multi-field similarity scoring
- ML model classification
- False negative reduction
While MLS systems with large volumes of listings can afford to make the transition from reactive to continuous listing verification, doing so represents the difference between having a reliable and credible database versus being a liability. To learn how HabileData can assist with providing this type of listing management solution at a large scale.
Real-World Result
A UK-based MLS platform attained high-performing, authenticated listing database that drove measurable business revenue growth for the platform’s broker subscribers. All this happened by integrating automated standardization, cleansing, and deduplication tool. Read more
Problem 4: Low-quality visual data reducing listing engagement and conversion
Listing images are not just design elements – they are also structural data assets. The amount of complete data, including how many images there are, what their resolution is, and whether all images are the same format can impact the search rankings and click through rate of a listing on an algorithm driven Multiple Listing Service (MLS) platform.
If a listing has poor property photos, misleading property photos or no images, then it will have a lower completeness score and therefore less visibility and longer days on market.
Listings that use professional photography get much more attention from buyers and sell faster than those that do not. Because some MLS platforms display listings based on how well engaged, they are, but the gap between the two types of listings grows larger over time.
Three data quality problems regarding visuals occur on almost all MLS platforms:

- Raw, un-edited photographs submitted by agents containing poor exposure, distorted perspectives, and inconsistent white balances.
- Inconsistent formats, resolutions and aspect ratios of images that result in rendering failure when viewed on other devices and/or sent to other listing syndication partners.
- Missing floor plans or virtual tour content. Buyers now expect these to be part of each listing and not just something extra to look at.
HDR editing, virtual staging, and 3D floor plans: What actually converts
To improve data quality on a large number of listings, you need a automated image editing post-processing pipeline.
Automated visual data validation and photo enhancement workflows
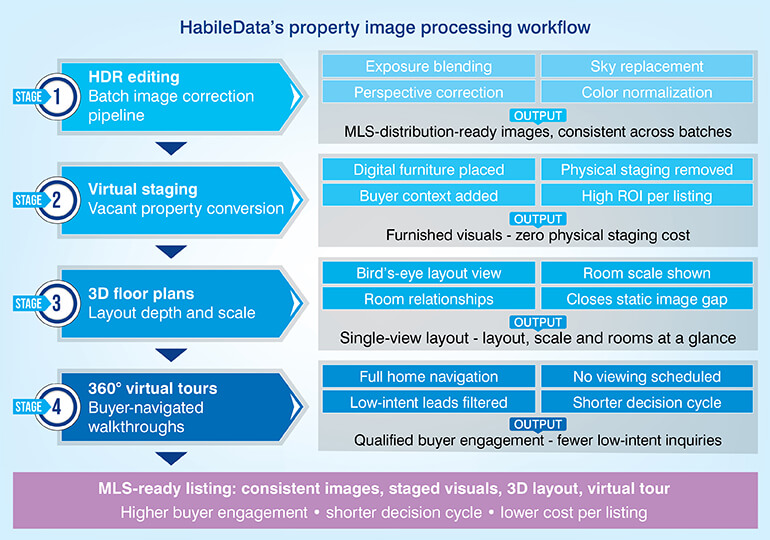
The automated post processing workflow includes:
- HDR editing (exposure blending), perspective correction, sky replacement and color normalization for entire batches of images; resulting in consistent images that meet MLS distribution standards.
- Virtual staging addresses one gap: vacant properties typically receive little to no buyer interest unless the buyer can visualize furniture in space.
- Using digital staging to remove the cost of physically staging a vacant property allows the buyer to obtain the spatial context needed to decide about purchasing the property. For residential platforms, this is a high ROI addition to any listing that was shot when the property was empty.
- Three-dimensional floor plans and 360-degree virtual tours help to close the depth gap created by static images. A 3-D floor plan provides a single view of the layout, size and relationship of rooms.
- Virtual tours allow buyers to navigate all areas of the home without having to schedule a viewing and results in fewer low-intent inquiries and a shorter decision-making process for serious buyers.
Real-World Result
A real estate photography company was able to leverage the benefits of an automated HDR post-processing pipeline of 3,500+ property images per batch. It significantly reduced the per-image processing costs alongside a measurable improvement in catalog image quality and platform brand positioning.
Want to manage property image quality at scale?
Let’s Connect »Problem 5: Scaling property listing management across high-volume databases
Off-the-shelf listing platforms have been created with traditional data structures and predictable volume expectations. The minute an aggregator scales across geographic regions, data source types or listing numbers, the limitations of the generic listing architecture are exposed.
Multi-data format data require multiple processing pipelines; text records, image files, video walk-throughs, PDFs, GIS shapefiles, and zoning documents each have their own specific schema expectations, quality degradation patterns, and refresh cadence expectations.
A single Content Management Layer will not support these diverse data formats without suffering Quality Drift. Compounding the problem is the fact that each datatype suffers from its own unique degradation problems when placed into a single pipeline.
As field definition expectations vary between source-types, text records begin to suffer from Inconsistency issues. Image Libraries fill up with duplicate images and unprocessed images.
Video walk-throughs become orphaned from parent listings after relisting events. If there are no separate processing paths for each datatype, the errors begin to build silently until they show themselves as User Complaints or Platform Audits.
Automated end-to-end property listing management workflows
The solution to the above problem is a Modular Pipeline Architecture each data-type has its own Processing Path, Quality Gate, Refresh Cycle and feeds a unified Listing Database at the Output Layer.
- Programmable Web Crawlers -Manage cross-time zone Data Acquisition, which ensures Listing Currency without Human Monitoring. Each crawler is designed specifically to each Source-Type based on the Source-Type’s Update Frequency, Data Structure and Anti-Scraping Profile.
- Automatic Scripts/Macros run Cleanse/Enrichment on a Schedule – Normalizes Field Formats, Fills Missing Values from Secondary Sources, and Flags Records Below Completeness Thresholds for Human Review.
- Human-in-the-Loop (HITL) Integration manages the Edge Cases that Full Automation cannot solve: Contested Ownership Records, Jurisdictional Legal Variations, and Non-Standard Property Types. HITL Workflows Embed Reviewers at Defined Checkpoints – Maintains Throughput while Ensuring Accuracy on Complex Records.

The result is a Listing Database where each Component is managed by the Process Best Suited to Manage That Component.
For those evaluating End-to-End Automation for their listing needs, HabileData Property Listing solutions covers the full pipeline of data acquisition, enrichment, image processing, verification and ongoing maintenance.
Real-World Result
End-to-end automated listing management solutions empowered a MLS platform to provide richer broker dashboards, accurate listing data, and real-time updates across residential and commercial property categories. This improved member service quality and operational efficiency.
How automation and AI are redefining property listing management
Automation in property listing management has moved beyond rule-based scripts. Modern platforms use ML extraction models, incremental learning, and real-time competitor intelligence to maintain data quality at scale. ML extraction models capture structured listing data from unstructured web sources without relying on fragile XPath or CSS selectors, reducing scraper failures when sites change.
Incremental learning keeps models updated as source structures evolve, lowering engineering effort across multiple data sources. The same infrastructure enables real-time competitor intelligence, tracking pricing shifts, inventory levels, days on market, and listing velocity. HabileData’s ISO-certified, BBB-accredited data operations support these systems with strict security protocols, confidentiality safeguards, and audit trails required by enterprise MLS and regulated real estate platforms.
Conclusion
The five challenges we discussed do not exist in silos but are connected to each other. Errors with real estate content can cause poor record keeping. Poor record keeping causes ghost listings. Ghost listings in their turn put off buyers. And such a broken data pipeline is hard to fix just by visual polish.
For actual improvements, we need the full stack. We need clean and accurate data ingestion, smart validation, live syncing of status changes and visual enhancements based on valid data.
MLS providers and aggregators now have a new question. How use automation to begin improving property listings online and decide benchmarks for each phase. Because platforms that get property listing optimization right will see brokers and customers engage more and will see higher rates of real estate lead conversion.
Frequently Asked Questions
The most common causes of inaccurate property listing data includes fragmented data sources, no schema normalization at the time of ingestion
Validation of property listing records depends largely on listing volumes, where high-volume platforms should validate their property records continuously on a near real-time basis. Property listing sites with medium volume should have weekly data validation batch cycles.
Deduplication in real estate data refers to the process of identifying and removing duplicate or dirty property records from a listing database. More than often same property with slight variation in address format, agent name, or property ID enters a database multiple times through different data sources. Without deduplication, real estate platforms will showcase conflicting records, ultimately confusing buyers and inflating apparent inventory.
Yes, expired listings do affect an MLS platform’s search engine performance. Crawlers when index a listing page and finds a 404 error or redirect after the property sells, they log it as a dead URL. A lot of dead listing URLs flags poor site health, which reduces crawl budget allocation for active pages, hides organic rankings which cuts down the traffic to live inventory.
RESO means Real Estate Standards Organization. They define data dictionaries and API standards that govern how property data is structured and exchanged across MLS systems. MLS data operators follow its standards because doing so reduces field-mapping conflicts during data ingestion, improve interoperability with third-party platforms, and maintain cleaner databases with fewer schema-related errors at scale.
Manual property data management is error prone, time consuming and incurs a lot of additional costs. It typically breaks down by the time active property records reach 5,000 and 10,000. This is where review cycles fail at keeping pace with incoming data velocity. Due to volumes error rates compound faster than teams can resolve. The cost per corrected record exceeds the cost of automated validation. Most MLS operators reach this position within their first two years of growth.
Facing property listing data challenges at scale?
Talk to real estate data experts »


Snehal Joshi , Head of Business Process Management at HabileData, leads a 500-member team of data professionals, having successfully delivered 500+ projects across B2B data aggregation, real estate, ecommerce, and manufacturing. His expertise spans data hygiene strategy, workflow automation, database management, and process optimization - making him a trusted voice on data quality and operational excellence for enterprises worldwide. 🔗Connect with Snehal on LinkedIn


