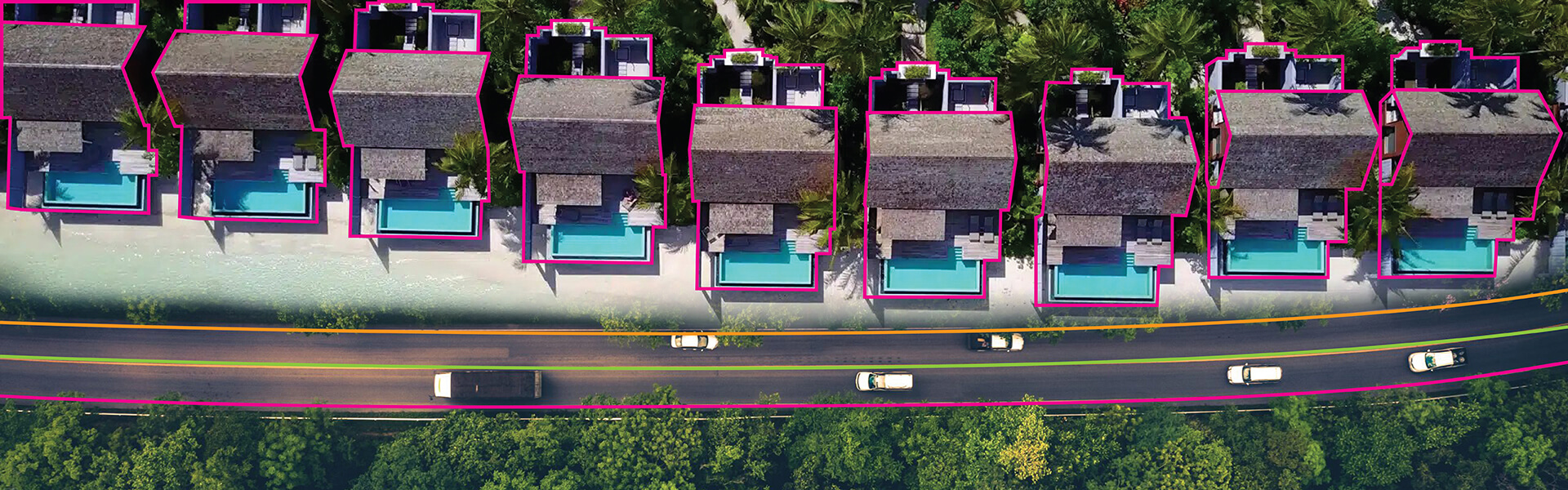
AI is transforming industries, and accurate AI data labeling is crucial for its success. Labeling provides the foundation for training machine learning models, enabling them to make precise predictions and decisions. High-quality labeled data is essential for AI to reach its full potential in various applications, from autonomous vehicles to medical diagnostics.
Contents
The rapid advancement of artificial intelligence (AI) is transforming industries, driving innovation, and reshaping how businesses operate in today’s digital era. Accurate AI data labeling lies at the heart of this success, as labeled data serves as the foundation for training effective machine learning (ML) models. Data labeling is the process of annotating raw data – such as images, text or videos – with meaningful tags or labels. This process enables supervised machine learning models to recognize patterns, make predictions, and deliver precise outcomes.
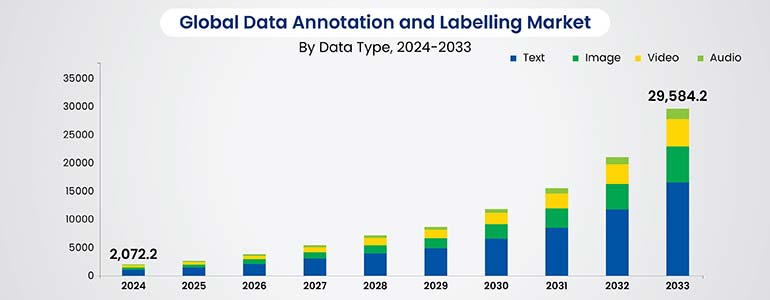
According to Dimension Market Research, the data annotation and labelling market is expected to grow to USD 29,584.2 million by the end of 2033, growing at a CAGR of 34.4%.
Without high-quality labeled data, AI systems struggle to achieve the accuracy needed for real-world applications. From autonomous vehicles to medical diagnostics, the demand for precisely annotated datasets is skyrocketing as AI adoption accelerates. In this article, we explore the critical role of data labeling in achieving precision in machine learning and its impact on advancing AI technologies across industries.
Importance of precision in machine learning
Artificial intelligence stands strong with precision. It is a crucial metric that measures the accuracy of positive predictions, specifically the proportion of true positives among all instances predicted as positive and is vital when minimizing false positives is paramount. Machine learning models are tasked with making accurate predictions, classifications and decisions based on the data they are trained on. Achieving high precision is crucial for building reliable and trustworthy AI systems that can be deployed in real-world applications.

Precision in machine learning refers to a model’s ability to consistently produce accurate and reliable results. It encompasses several key aspects, including:
- Accuracy: The model’s ability to correctly predict or classify outcomes.
- Generalization: The model’s ability to perform well on new, unseen data, not just the data it was trained on.
- Reliable Predictions: The model’s ability to produce consistent and dependable predictions across different scenarios and datasets.
However, there are several factors that influence the precision of machine learning models. Let’s check them out.
- Data Quality: High-quality data, including accurate labels and relevant features, is essential for training precise models.
- Algorithm Selection: Choosing the right algorithm for the specific task and data characteristics is crucial for achieving optimal precision.
- Model Training: Proper training procedures, including hyper parameter tuning and regularization techniques, can significantly impact model precision.
Precision is the hallmark of successful machine learning models. By focusing on data quality, algorithm selection, and effective training strategies, we can build AI systems that deliver accurate, reliable, and impactful results across various domains.
Want high-quality data labeling to drive precision in your machine learning models?
Contact us today »How accurate AI data labeling drives precision
Precision is the gold standard when it comes to machine learning. AI models must be able to make accurate predictions, classifications and decisions based on the data they are trained on. And the key to achieving this precision lies in the accuracy of the data labeling process. Accurate data labeling is the foundation upon which successful AI systems are built, enabling them to learn, adapt and perform with high precision.
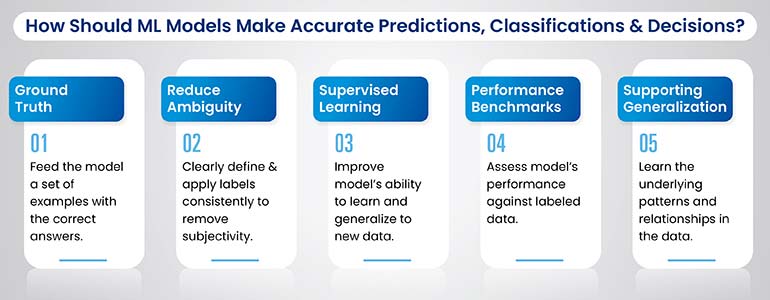
Providing Ground Truth: Data labeling provides the “ground truth” for machine learning models. It’s like giving the model a set of examples with the correct answers. For instance, in image recognition, labels identify objects, scenes and attributes within images, telling the model what it’s looking at. This ground truth allows the model to learn the relationship between the input data (the image) and the desired output (the labels), enabling it to make accurate predictions about new, unseen data.
Reducing Ambiguity: Consistent and accurate data labeling reduces ambiguity and ensures clarity for machine learning models. When labels are clearly defined and applied consistently, they remove the scope for subjective interpretation. This consistency is crucial because even slight variations in labeling can confuse the model and lead to inaccurate predictions. By establishing clear labeling guidelines and ensuring adherence to them, we can improve the accuracy and reliability of AI models.
Enabling Supervised Learning: Labeled data is the cornerstone of supervised learning, a dominant paradigm in machine learning. In supervised learning, models learn by analyzing labeled examples and identifying patterns in the data. Different supervised learning algorithms, such as decision trees, support vector machines and neural networks, rely on labeled data to learn and make predictions. The quality and accuracy of the labels directly affect the model’s ability to learn and generalize to new data.
Establishing Performance Benchmarks: Labeled data serves as a benchmark against which machine learning model performance is measured. By comparing the model’s predictions to the ground truth labels, we can evaluate its accuracy and identify areas for improvement. This evaluation process is crucial for optimizing model performance and ensuring that it meets the desired precision levels. Metrics such as accuracy, precision, recall, and F1-score are commonly used to assess the performance of machine learning models against labeled data.
Supporting Generalization: Data labeling supports the generalization ability of machine learning models. Generalization refers to the model’s ability to accurately predict labels for new, unseen data, not just the data on which it was trained. By providing a diverse and representative set of labeled examples, we can help the model learn the underlying patterns and relationships in the data, enabling it to apply this knowledge to new situations and make accurate predictions about unseen data.
Accurate data labeling is not just a task; it is a strategic process that drives the precision and success of AI initiatives. By providing ground truth, reducing ambiguity, enabling supervised learning, establishing performance benchmarks, and supporting generalization, accurate data labeling empowers machine-learning models to achieve high precision and deliver impactful results across various applications.
It’s time you unlock the full potential of your AI with accurate and consistent data labeling.
Reach out to us today »3 common data labeling challenges for AI companies
While data labeling is crucial for AI development, it’s not without its challenges. These challenges can impact the accuracy, efficiency, and scalability of the labeling process, ultimately affecting the performance and reliability of AI models. Addressing these challenges is essential for ensuring high-quality labeled data and maximizing the potential of AI initiatives.

Data Quality and Consistency: Maintaining high quality and consistency in labeled data, especially with large datasets, can be a significant challenge. Variations in human judgment, subjective interpretations, and fatigue can lead to inconsistencies in labeling. Clear guidelines, comprehensive training, and ongoing quality control measures are crucial for minimizing errors and ensuring consistency across annotators. Inter-annotator agreement, a measure of how often multiple annotators agree on the same label, is a key metric for assessing data quality.
Bias and Subjectivity: Bias in data labeling can inadvertently introduce biases into AI models, leading to unfair or discriminatory outcomes. Human annotators may have unconscious biases that influence their labeling decisions, and these biases can be amplified by the AI model. Strategies to mitigate bias include using diverse annotation teams, implementing bias detection tools, and carefully reviewing labeling guidelines to ensure fairness and objectivity.
Scalability and Cost: Scaling data labeling efforts to meet the growing demands of AI projects can be challenging. Traditional manual labeling approaches can be time-consuming and expensive, especially for large datasets. Efficient workflows, automation tools, and cost-effective annotation solutions are essential for scaling labeling operations while maintaining quality and affordability. Active learning, a technique that strategically selects the most informative data points for labeling, can also help improve efficiency and reduce costs.
Despite these challenges, the field of data labeling is constantly evolving, with new tools, techniques and best practices emerging to address these issues. By acknowledging and proactively addressing these challenges, we can ensure high-quality labeled data that drives the precision and success of AI applications.
How much does data labeling cost?
Data labeling is an essential investment for AI development, but it can also be a significant expense. Understanding the factors that influence data labeling costs and exploring cost-saving strategies is crucial for managing budgets and ensuring the feasibility of AI projects.
Several factors contribute to the overall cost of data labeling:
- Data Complexity: Complex data, such as medical images or dense text, require more specialized expertise and time to label, increasing costs.
- Annotation Type: Different annotation types, such as bounding boxes, semantic segmentation or text transcription, have varying levels of complexity and cost.
- Required Accuracy: Higher accuracy requirements necessitate more rigorous quality control measures and potentially multiple rounds of annotation, driving up costs.
- Labor Costs: Labor costs vary depending on the location, expertise, and experience of the annotators.
For example, a project requiring highly specialized medical image annotation by expert annotators in the US will likely be more expensive than a project involving simple image tagging by crowdsourced workers.
Here are a few strategies that can help you optimize the cost of your data labeling projects:
- Automation Tools: Automation tools can streamline repetitive tasks, reduce manual effort, and improve efficiency, leading to cost savings.
- Outsourcing: Outsourcing data labeling to specialized providers can offer cost advantages and access to skilled annotators.
- Crowdsourcing Platforms: Crowdsourcing platforms provide access to a large pool of annotators at competitive rates, particularly for simpler tasks.
However, it’s important to consider the trade-offs among cost, quality, and speed. While cost-saving measures can be beneficial, they should not compromise the accuracy or reliability of the labeled data.
By carefully considering the factors that influence cost and implementing appropriate cost-saving strategies, AI and ML companies can effectively manage data labeling expenses while ensuring high-quality labeled data for their AI initiatives.
What is the difference between data labeling and data annotation?
The terms “data labeling” and “data annotation” are often used interchangeably, but there is a subtle distinction between them. Understanding this difference can help clarify terminology and ensure effective communication in AI projects.
| Feature | Data Labeling | Data Annotation |
|---|---|---|
| Core Task |
|
|
| Information Added |
|
|
| Complexity |
|
|
Clarifying the Terminology – Data labeling is a subset of data annotation. It specifically refers to the process of adding labels or tags to data, such as assigning a category label to an image or labeling a sentence as positive or negative sentiment. Data annotation, on the other hand, is a broader term that encompasses various techniques for adding metadata to data, including labeling, as well as more complex tasks like drawing bounding boxes around objects, transcribing speech, or segmenting images.
Illustrating with Examples – To illustrate the difference, consider an image of a cat. Data labeling involves simply assigning the label “cat” to the image. Data annotation, however, could involve drawing a bounding box around the cat in the image, identifying its key features (eyes, ears, tail), or even segmenting the image to separate the cat from the background.
Both data labeling and data annotation play crucial roles in preparing data for AI. Data labeling provides basic categorization, while data annotation adds richer information that enables more sophisticated AI applications.
Conclusion
Precise data labeling is the cornerstone of achieving accuracy and reliability in machine learning. High-quality labeled data empowers AI models to learn effectively, make accurate predictions, and generalize to new situations. By addressing challenges related to data quality, bias, and scalability, we can ensure that labeled data fuels the success of AI initiatives. As the field of AI continues to evolve, the importance of data labeling will only grow. Continuous innovation and improvement in data labeling techniques and practices will be essential for shaping the future of AI and unlocking its full potential across various domains.
Struggling to find reliable, cost-effective data labeling that delivers precision and excellence?
Reach out to us today »


HabileData is a global provider of data management and business process outsourcing solutions, empowering enterprises with over 25 years of industry expertise. Alongside our core offerings - data processing, digitization, and document management - we’re at the forefront of AI enablement services. We support machine learning initiatives through high-quality data annotation, image labeling, and data aggregation, ensuring AI models are trained with precision and scale. From real estate and ITES to retail and Ecommerce, our content reflects real-world knowledge gained from delivering scalable, human-in-the-loop data services to clients worldwide.