
Synthetic data gives our teams realistic, shareable datasets when real logs are scarce or sensitive. With synthetic data generation using rules, simulations, GANs and diffusion models, you can balance classes, cover edge cases and support privacy preserving AI training.
Contents
- What is synthetic data
- Basic types of synthetic data generation
- Various synthetic data types
- Synthetic data examples in action
- Real-world use cases of synthetic data
- Synthetic data benefits for machine learning
- Synthetic data challenges and limitations
- How synthetic data generation services solve these challenges
- Future of synthetic data generation
- Conclusion
Synthetic data is data made by algorithms to mirror the patterns in real datasets. Teams build it with probabilistic models, simulations, GANs, VAEs, diffusion models and even large language models. The aim is simple. Create synthetic data that behaves like the source so machine learning pipelines can learn useful signals without exposing people or sensitive records. Before it goes into training, our AI teams use standard texts and reports to check whether the data has enough utility and low privacy risk.
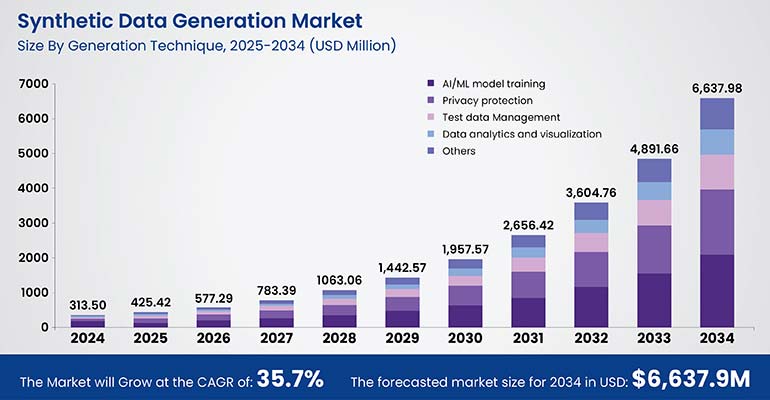
The global Synthetic Data Generation market is projected to rise from USD 313.50 million in 2024 to USD 6,637.98 million by 2034. It was dominated by text data in 2024, followed by fully synthetic and agent based systems. AI/ML model training was the leading application, but now healthcare and life sciences are emerging as the top industry adopter, highlighting rising demand for privacy focused, high quality training data.
Adoption is growing because the gains are practical: safer sharing, faster iteration and better coverage of edge cases. Still, you need guardrails. A generator that copies its source too closely can leak details. Bias in the source can pass through if you don’t test for it. And models that feed on machine made samples for too long can drift. The fix is straightforward in intent: validate quality, watch privacy and keep real and synthetic data in balance.
This article sets up the basics, then moves into examples, context for synthetic vs real data, key methods, use cases, benefits, the main ways to generate synthetic data and the limits you should plan for.
What is synthetic data
Synthetic data is artificial data created by algorithms to reproduce the statistical shape of a real dataset. Think distributions, correlations, constraints and natural ranges. With synthetic data generation, our teams use probabilistic modeling, generative AI for datasets and simulation based training data to produce records that behave like the source. In day to day work, engineers build structured synthetic data that respects schema, primary keys and business rules. It proves that you get useful signals for training and testing without touching live records.
Then, how does synthetic data compare to real data

The difference between synthetic data and real data is exposure. Real data describes actual people, devices and events. Synthetic vs real data matters because synthetic data imitates patterns without revealing real identities. When quality checks pass, the result keeps a strong utility for model development while lowering privacy risk and easing data sharing across teams or vendors.
Common methods that support synthetic data
How it is made varies by goal and data type.
- GAN-generated datasets work well when you need realistic images or complex tabular patterns.
- VAEs compress samples, then decode new variants that still feel coherent.
- Diffusion models start from noise and step toward high fidelity outputs.
- Agent based simulations recreate behavior over time for traffic, logistics, finance or fraud.
- Rule based generators add constraints and controlled noise when you need determinism and auditability.
Together, this is how we cover most synthetic data types used by ML models, from time series to text.
Why does it matter now
So why does it matter now? It all comes down to pressure and pace. Teams need privacy preserving AI training, faster iteration and better coverage of rare edge cases. Synthetic data helps fill empty classes, stage controlled experiments and unblock collaboration when access to production is limited. Still, it’s not a free pass. If the source is biased, the bias can carry over. If you rely only on machine made samples, model quality can drift. The cure is careful validation, honest measurement and a steady mix of real and synthetic data.
Unlock the potential of your AI/ML models with synthetic data generation.
Know more here »Basic types of synthetic data generation
There are 3 practical ways we create synthetic data. We can write rules. We can simulate the world. Or we can train models that learn patterns and produce new samples. The choice depends on your data type, your privacy goals and how much control you need.
Rule-based generation
Using algorithms and simulations:
We start with rules when we want control. You define constraints, distributions and business logic, then sample from them. Ages stay within real ranges, foreign keys line up, seasons drive demand and time gaps look natural.
Example: A retail team might script daily transaction volumes, use a log normal curve for amounts and shift category mix on weekends. They may add a handful of odd, out of geo purchases at 2 a.m. to test fraud rules. The result is structured synthetic data that respects schema, keeps relationships intact and easily adjusts according to requirements.
Machine learning models (e.g., GANs)
Generative Adversarial Networks explained simply:
Use machine learning based generators when patterns get complex.
GANs pit 2 networks against each other; one generates candidates and the other judges whether they look real, until the generator improves. Diffusion models move from noise to clean samples in small steps. VAEs compress examples into a latent space and decode fresh variants.
Example: An imaging team short on underrepresented faces, tricky lighting or rare angles can expand coverage with GAN generated datasets, then check class balance and realism before training. That widens the data without collecting more sensitive images.
Data augmentation techniques
Techniques for image, video, and text:
Data augmentation is the quick boost. You start with real samples and create safe variants. In images and video, you crop, rotate, blur, add noise or synthesize intermediate frames using diffusion methods.
Examples: In tabular work, you nudge values within valid bounds to probe decision edges. In text, we generate paraphrases, summaries and dialogues to cover more intents. This supports privacy preserving AI training and helps stress test robustness when original data is limited or sensitive.
Most of our teams blend these paths. Rules give clarity and audit trails. Generative models capture rich structure. Augmentation fills gaps fast. Used together, synthetic data generation produces artificial data that matches real patterns closely enough for training and testing, while keeping real people out of view.
Various synthetic data types
Synthetic data isn’t one size fits all. Tables, images, video, text and time series carry different signals, so synthetic data generation uses different tools for each.
- Structured synthetic data needs schema and keys.
- Images and video need light, motion, and depth.
- Text needs grammar and intent.
- Sensors need rhythm and noise.
The goal stays the same. We need to keep useful patterns for ML while supporting privacy preserving AI training.
How are popular types of synthetic data generated
| Type | What it covers | How it’s generated | Quick example | Where it helps |
|---|---|---|---|---|
| Tabular | Customer transactions, health records, IoT device logs | Statistical sampling, copulas, GANs | Simulate card swipes with seasonality and rare fraud spikes | Balanced classes, safe vendor sharing |
| Image | Photos, scans | Computer graphics, GANs, diffusion models | AV scenes with varied lighting, weather, occlusion | Edge case coverage without real faces |
| Video | Sequences with motion and timing | Simulated worlds, motion capture, 3D rendering | Surveillance clips that change camera height and crowd flow | Re-identification, robotics navigation |
| Text | Dialogues, FAQs, labeled corpora | LLM prompts and templates | New intents for chatbot training or sentiment analysis | Privacy preserving AI training, broader coverage |
| Time series | Sensors, finance, energy demand | Sequence GANs, autoregressive models, SDEs | Weekday peaks and weather shocks for forecasting | Stress tests without production logs |
| Domain-specific | Healthcare, finance, manufacturing, defense | Domain constraints, fairness checks, compliance rules | Patient flows with valid codes and dosage ranges | Policy aligned datasets that still feel real |
Synthetic data examples in action
Fraud detection
Fraud is rare and messy. But models need to see it anyway. We build synthetic transactions that look normal at first, then slip in odd patterns: 3 swipes in a minute, out of geo purchases at 2 am, a split bill at a high risk merchant. The model learns what “off” looks like without exposing a single real cardholder.
Autonomous driving
Real roads rarely give you every edge case you need. Synthetic scenes do. Our engineers script jaywalking at night, rain on the lens, headlight glare and a cyclist cutting in near a junction. They tweak light, weather, timing, even camera angle. Perception models get steady practice on the cases that matter most.
Predictive modeling in healthcare
Access to clinical data is tight for good reasons. Synthetic EHRs mirror codes, labs, vitals and care about timelines while removing direct identifiers. Teams train risk or diagnostic models, then check utility and privacy before any deployment. It not only supports privacy but preserves AI training and helps the work to move forward without waiting months for approvals.
NLP for low-resource languages
Some languages lack big corpora. Synthetic text fills gaps with short dialogues, FAQs and labeled snippets made under clear rules. You set topic and tone, then review samples to curb bias and noise. Models gain coverage for intent, sentiment or NER without scraping sensitive messages.
Finance and time series modeling
Markets shift in regimes. You need calm days and shocks. Synthetic time series create both. Our teams mix sequence GANs with simple stochastic models to form realistic price paths and order flow patterns. Strategy tests become broader and repeatable, not tied to last quarter’s mood.
Across these cases, the pattern holds. We use synthetic data to create hard but safe examples. Keep checks on quality and drift. And give your ML models the practice they can’t get from real data alone.
Real-world use cases of synthetic data
AI/ML development acceleration
Our teams need data that fits the task, not the other way around. Synthetic data use cases start here. Engineers spin up scalable, balanced datasets that match target schemas and label mixes. Models train, fail and improve in quick loops because new samples are just a runaway. The result? Faster iteration and cleaner offline evaluation before we touch any real data.
Data privacy and compliance
Regulated data slows projects. GDPR and HIPAA add strict guardrails. Privacy-preserving AI training with synthetic data helps by removing direct identifiers and lowering re-identification risk. Teams share structured synthetic data across vendors and environments with clear policies, audits, and utility checks. You keep velocity while staying within the rules.
Rare event simulation
Real logs rarely show enough edge cases. Simulation-based training data fills the gap. Fraud spikes, cybersecurity anomalies, medical outliers, manufacturing defects. You script patterns or learn them with GANs, then generate controlled bursts that reflect reality. Models see more of the hard stuff, which sharpens detection and recall.
Bias mitigation and fairness
Synthetic vs real data often shows the same problem: skewed coverage. With synthetic generation, our teams create balanced demographic slices and equalize classes such as age ranges, skin tones or device types. We still test for drift and leakage, but now we can study fairness metrics with the coverage we actually need.
Model testing and validation
Before production, systems need stress. Synthetic data lets you stage outages, odd timing, class clashes and domain shifts on demand. You probe thresholds, reliability and fail-safes without risking live users. Logs from these runs become a repeatable test bed for every new model build.
Want to leverage our synthetic data generation services?
Contact us now »Synthetic data benefits for machine learning
Data availability at scale
Data availability at scale You don’t wait months for collection and approvals. Synthetic data generation produces large, task ready sets that mirror real distributions and constraints. Work moves from “blocked” to “building”.
Privacy and compliance
No direct PII or PHI. With proper fit tests and privacy reviews, teams share artificial data safely across tools and partners. This supports audits and reduces exposure.
Cost efficiency
Less manual collection. Less labeling from scratch. You generate balanced labels, rare cases and long tails as needed. Budgets stretch further, especially in early R&D.
Bias reduction and diversity
Coverage improves when you can create missing slices. Our teams add underrepresented groups, rare conditions and device types, then measure fairness with standard metrics.
Model robustness
Stress testing gets real. We script shocks, seasonality shifts and noise. Models learn to hold their ground under messy conditions, not just happy paths.
Rapid prototyping
Ideas reach a working demo faster. Structured synthetic data plugs into the pipeline on day 1, so product teams can test flows, tune features and plan go to market with fewer stalls.
Synthetic data challenges and limitations
| Challenge | Why it matters | Impact if ignored | What helps |
|---|---|---|---|
| Fidelity vs. realism gap | Data may look right but miss true joint patterns or edge behavior | Overfit on easy signals, poor lift in production | Calibrate to real baselines, compare marginals and joint stats, run task-level utility tests |
| Mode collapse in generators | GANs or diffusion models may repeat safe samples and skip rare modes | Weak diversity, blind spots on hard cases | Use advanced generators, tune objectives, add diversity penalties, mix in real slices |
| Lack of domain expertise | Small rule mistakes create artifacts that models learn the wrong way | Spurious features, false confidence, compliance risk | Pair data scientists with SMEs, write explicit constraints, review with red-team checks |
| Evaluation is tricky | Quality, utility, and privacy pull in different directions | Good looking data that underperforms or leaks | Multi metric scorecards: task utility, statistical fidelity, privacy risk; hold-out tests |
| Privacy leakage | Overfitting can echo real records | Re-identification risk, legal exposure | Overfit guards, distance to nearest checks, privacy audits, k-anonymity–style screens |
| Operational drift | Generators age as real data shifts | Silent degradation and slow model decay | Scheduled re-training, drift monitors, periodic side-by-side runs with fresh real samples |
| Transition to solutions | Teams need a path from “known issues” to fixes | Rework and stalled adoption | Bring in domain-specific expertise, adopt advanced generators, keep a blend of real and synthetic |
How synthetic data generation services solve these challenges
Good providers make synthetic data work at scale. They start with quality. Structured synthetic data is checked against real baselines, joint patterns and task scores. Privacy is baked in with controls for privacy preserving AI training and reviews that align with GDPR and HIPAA. Then comes scale. Clean pipelines produce repeatable datasets on time, so our engineering teams can build without stalls.
Synthetic data and our offerings
Our services cover the core shapes your models need. For tabular data, we generate balanced customer records and IoT logs that keep schema, keys and rules intact.
- For image work, we mix computer graphics with GANs and diffusion models to handle lighting, texture and occlusion.
- For video, we render motion, timing and camera shifts so sequences feel believable.
- For text, we create labeled corpora with large language models and strict prompts, filters and human review.
- For time series, we model seasonality, shocks and drift so forecasts hold up.
- For domain specific needs, we add policy rules, audit trails, and sign-offs from day 1.
Domain expertise is a huge differentiator.
- In healthcare, we align codes, dosage ranges and care timelines while protecting PHI.
- In finance, we simulate order books, venue rules, and latency for fair testing.
- In autonomous systems, we script light, weather and behavior to stage hard scenes safely.
The result is synthetic data generation that’s reliable, compliant and ready for ML pipelines.
Future of synthetic data generation
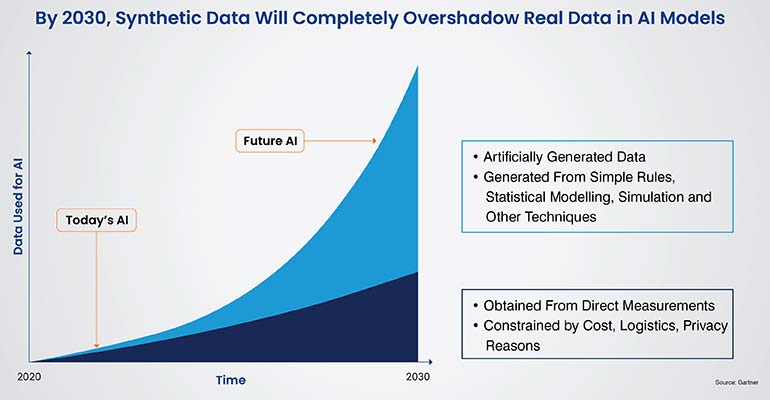
Smarter generators
Diffusion models push fidelity higher with stable training. Foundation models shorten setup by learning broad patterns you can adapt fast. Together, they raise the ceiling on image, video, text and time series quality while cutting the time from idea to dataset.
Clearer rules
Regulators are moving toward practical guidance on privacy preserving AI training. That shift gives teams a safer path to share structured synthetic data across vendors and regions. We expect tighter audits, standard tests for re-identification risk and more green lights for controlled pilots.
New arenas
Digital twins, robotics and metaverse style simulations demand long sequences, realistic physics and repeatable scenes. Synthetic data fills that need. You can script rare events, scale to thousands of runs and keep logs consistent for model testing and validation.
Default first step
Most projects will start with synthetic data, then ground results with a small, well governed slice of real data. The payoff is speed, safer iteration and stronger checkpoints before production. As tooling matures and policies settle, this workflow becomes routine: generate, validate, blend, ship.
Conclusion
Synthetic data answers a basic need. Our teams require useful data on time, with privacy and compliance in place. It delivers availability at scale, safer sharing and better coverage of rare cases. Models train faster and handle tougher tests.
Keep validation tight and keep a healthy mix of synthetic vs real data. Results improve, risk falls and projects move. Adoption will rise as tools mature and rules settle. If you want your AI and ML to move faster and stay robust, start building with synthetic data now.
Nail synthetic data generation across images, videos, text, time-series, and more.
Get benefit from our services today »


Snehal Joshi , Head of Business Process Management at HabileData, leads a 500-member team of data professionals, having successfully delivered 500+ projects across B2B data aggregation, real estate, ecommerce, and manufacturing. His expertise spans data hygiene strategy, workflow automation, database management, and process optimization - making him a trusted voice on data quality and operational excellence for enterprises worldwide. 🔗Connect with Snehal on LinkedIn


